Some of you might have noticed that TextParse.jl (and CSVFiles.jl, which is a small wrapper around TextParse.jl) saw some major performance regressions initially on julia 1.0.
I just fixed these and now both packages are back to the kind of performance that we saw on julia 0.6 for them (which was pretty good). If you had given up on either package since moving to julia 1.0, I encourage you to give them another try, they should be very usable again.
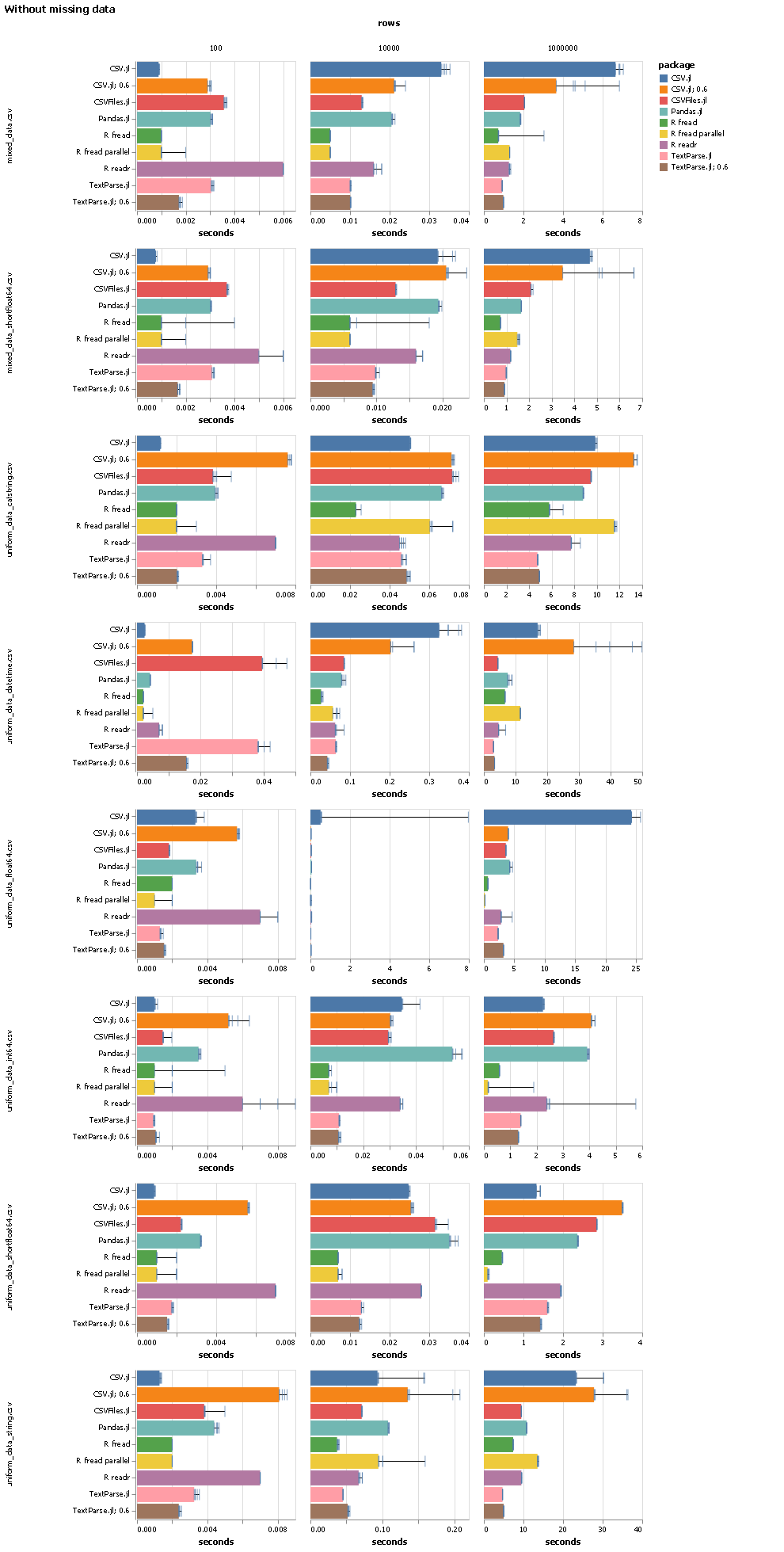
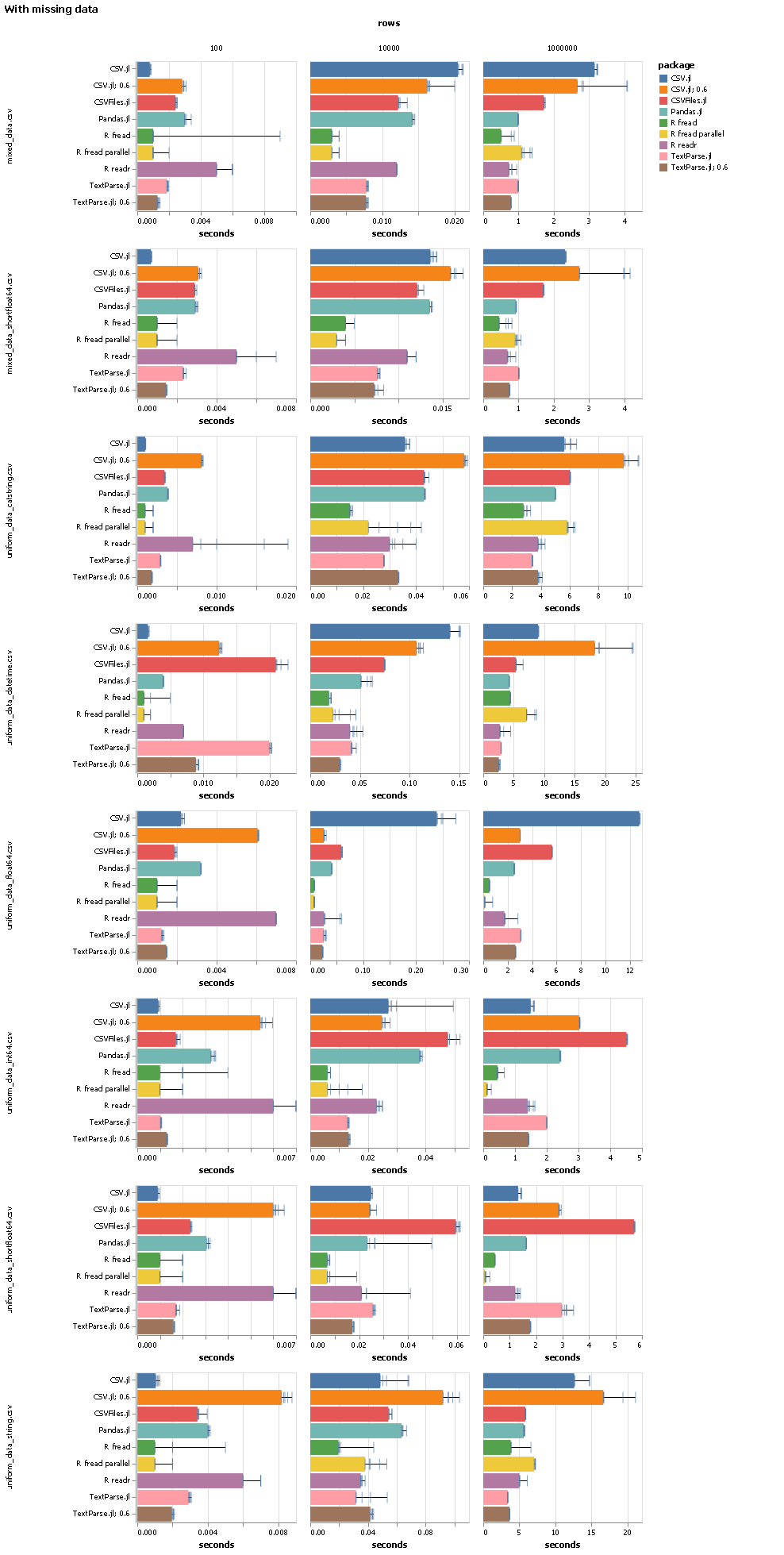
As part of that work I also wrote a benchmark that compares various CSV reading packages on julia, Python and R. The high-level summary is that R’s fread beats pretty much everything, but other than that TextParse.jl is (and was on julia 0.6) looking pretty good.
Here are the detailed results:


{kind=link}
{kind=link}
I used the currently latest tagged version of all packages that are tested. A “; 0.6” in the package name means this run was done on julia 0.6. I ran every benchmark five times. The bar shows the best of those five runs, and all five runs are shown as ticks. The different files have different types of data in the columns: the files with “mixed” in the name have one column of float, int, string, categorical string (a string column that only ever has a few different values) and datetime. The files with “uniform” in the name have 20 columns all with the same data type. “short” in the filename signals that floating point numbers don’t have more than 6 digits.