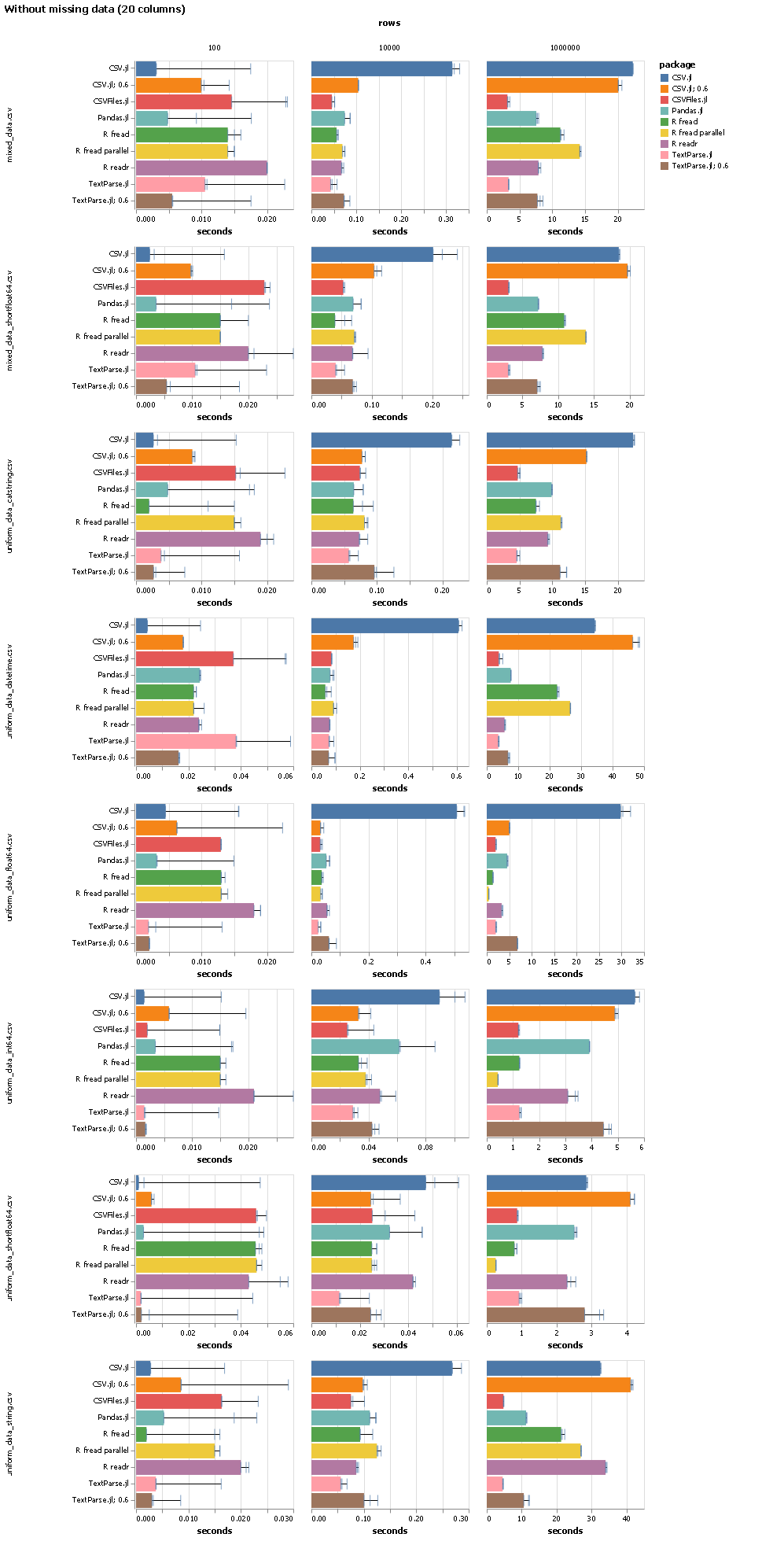
I can’t reproduce your timings… for a 100,000 x 12 table of random floats, I get 70ms with Julia and 129ms with Pandas.
Performance does suffer a bit with mixed types. In t2.csv, I changed the first column to ints (notice the huge increase in allocations), but still nothing like your timings. What types are you using?
shell> wc -l /tmp/t.csv
100001 /tmp/t.csv
shell> head /tmp/t.csv
k,m,i,l,p,b,e,o,d,n,a,c
0.2409627,0.4039211,0.1651225,0.5667682,0.5894277,0.9943912,0.547174,0.8407955,0.4460115,0.3069141,0.6926464,0.8103599
0.9240403,0.7549936,0.6487547,0.8099625,0.1726365,0.8733207,0.6790217,0.4219462,0.3477867,0.8507886,0.8026299,0.2950769
0.4712006,0.439265,0.4611259,0.4271396,0.02038192,0.8205912,0.8553605,0.02757602,0.2683213,0.8179719,0.7291129,0.06494521
0.996349,0.2351459,0.5336153,0.369024,0.1737951,0.779296,0.694431,0.5706579,0.3687971,0.7410107,0.9468887,0.9853139
0.8812785,0.06228102,0.4772179,0.4879081,0.5711414,0.7249674,0.7723914,0.3086208,0.9367701,0.3911373,0.7716293,0.8062436
0.2830349,0.2336157,0.03236917,0.375143,0.4423652,0.4979272,0.6796134,0.2883468,0.5686293,0.04900234,0.6169183,0.02231071
0.464235,0.4393972,0.7299044,0.7271473,0.644167,0.1910563,0.9823838,0.01284925,0.7959115,0.5527272,0.08613271,0.1721825
0.404164,0.01794849,0.8456904,0.9365643,0.3868644,0.4041997,0.8453569,0.136697,0.8901002,0.500644,0.1406727,0.3415088
0.6361285,0.6320285,0.6464563,0.8733505,0.04576213,0.6102426,0.3786439,0.2345142,0.2210209,0.5040782,0.5065185,0.2678539
julia> @benchmark CSV.read("/tmp/t.csv")
BenchmarkTools.Trial:
memory estimate: 12.31 MiB
allocs estimate: 196
--------------
minimum time: 68.950 ms (0.00% GC)
median time: 69.678 ms (0.70% GC)
mean time: 70.810 ms (2.27% GC)
maximum time: 118.171 ms (40.81% GC)
--------------
samples: 71
evals/sample: 1
shell> wc -l /tmp/t2.csv
100001 /tmp/t2.csv
shell> head /tmp/t2.csv
k,m,i,l,p,b,e,o,d,n,a,c
5,0.4039211,0.1651225,0.5667682,0.5894277,0.9943912,0.547174,0.8407955,0.4460115,0.3069141,0.6926464,0.8103599
3,0.7549936,0.6487547,0.8099625,0.1726365,0.8733207,0.6790217,0.4219462,0.3477867,0.8507886,0.8026299,0.2950769
6,0.439265,0.4611259,0.4271396,0.02038192,0.8205912,0.8553605,0.02757602,0.2683213,0.8179719,0.7291129,0.06494521
7,0.2351459,0.5336153,0.369024,0.1737951,0.779296,0.694431,0.5706579,0.3687971,0.7410107,0.9468887,0.9853139
0,0.06228102,0.4772179,0.4879081,0.5711414,0.7249674,0.7723914,0.3086208,0.9367701,0.3911373,0.7716293,0.8062436
2,0.2336157,0.03236917,0.375143,0.4423652,0.4979272,0.6796134,0.2883468,0.5686293,0.04900234,0.6169183,0.02231071
2,0.4393972,0.7299044,0.7271473,0.644167,0.1910563,0.9823838,0.01284925,0.7959115,0.5527272,0.08613271,0.1721825
3,0.01794849,0.8456904,0.9365643,0.3868644,0.4041997,0.8453569,0.136697,0.8901002,0.500644,0.1406727,0.3415088
9,0.6320285,0.6464563,0.8733505,0.04576213,0.6102426,0.3786439,0.2345142,0.2210209,0.5040782,0.5065185,0.2678539
julia> @benchmark CSV.read("/tmp/t2.csv")
BenchmarkTools.Trial:
memory estimate: 47.32 MiB
allocs estimate: 2294086
--------------
minimum time: 95.924 ms (1.56% GC)
median time: 96.489 ms (1.58% GC)
mean time: 98.969 ms (3.59% GC)
maximum time: 154.921 ms (33.72% GC)
--------------
samples: 51
evals/sample: 1
julia> @benchmark Pandas.read_csv("/tmp/t.csv")
BenchmarkTools.Trial:
memory estimate: 11.36 KiB
allocs estimate: 97
--------------
minimum time: 126.454 ms (0.00% GC)
median time: 129.265 ms (0.00% GC)
mean time: 129.198 ms (0.00% GC)
maximum time: 131.443 ms (0.00% GC)
--------------
samples: 39
evals/sample: 1
julia> @benchmark Pandas.read_csv("/tmp/t2.csv")
BenchmarkTools.Trial:
memory estimate: 11.36 KiB
allocs estimate: 97
--------------
minimum time: 120.393 ms (0.00% GC)
median time: 123.140 ms (0.00% GC)
mean time: 122.649 ms (0.00% GC)
maximum time: 124.729 ms (0.00% GC)
--------------
samples: 41
evals/sample: 1
julia> versioninfo(verbose=true)
Julia Version 1.2.0-DEV.unknown
Commit 60457de* (2019-03-08 17:26 UTC)
Platform Info:
OS: Linux (x86_64-pc-linux-gnu)
uname: Linux 4.4.0-116-generic #140-Ubuntu SMP Mon Feb 12 21:23:04 UTC 2018 x86_64 unknown
CPU: Intel(R) Xeon(R) CPU E3-1220 v5 @ 3.00GHz:
speed user nice sys idle irq
#1 3500 MHz 3792225 s 9640 s 88120 s 373573962 s 0 s
#2 3474 MHz 1353493 s 12106 s 65979 s 377578307 s 0 s
#3 3500 MHz 1468507 s 13422 s 65814 s 377466150 s 0 s
#4 3480 MHz 1371725 s 13179 s 68439 s 377578218 s 0 s
Memory: 62.74964904785156 GB (27196.83203125 MB free)
Uptime: 3.790843e6 sec
Load Avg: 0.0 0.0322265625 0.0029296875
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-6.0.1 (ORCJIT, skylake)
Environment:
HOME = /home/me
TERM = screen-256color
PATH = /home/me/.cargo/bin:/home/me/.cargo/bin:/usr/local/sbin:/usr/local/bin:/usr/bin:/usr/bin/site_perl:/usr/bin/vendor_perl:/usr/bin/core_perl:/usr/bin/site_perl:/usr/bin/vendor_perl:/usr/bin/core_perl
{kind=link}