I just fixed these and now both packages are back to the kind of performance that we saw on julia 0.6 for them (which was pretty good). If you had given up on either package since moving to julia 1.0, I encourage you to give them another try, they should be very usable again.
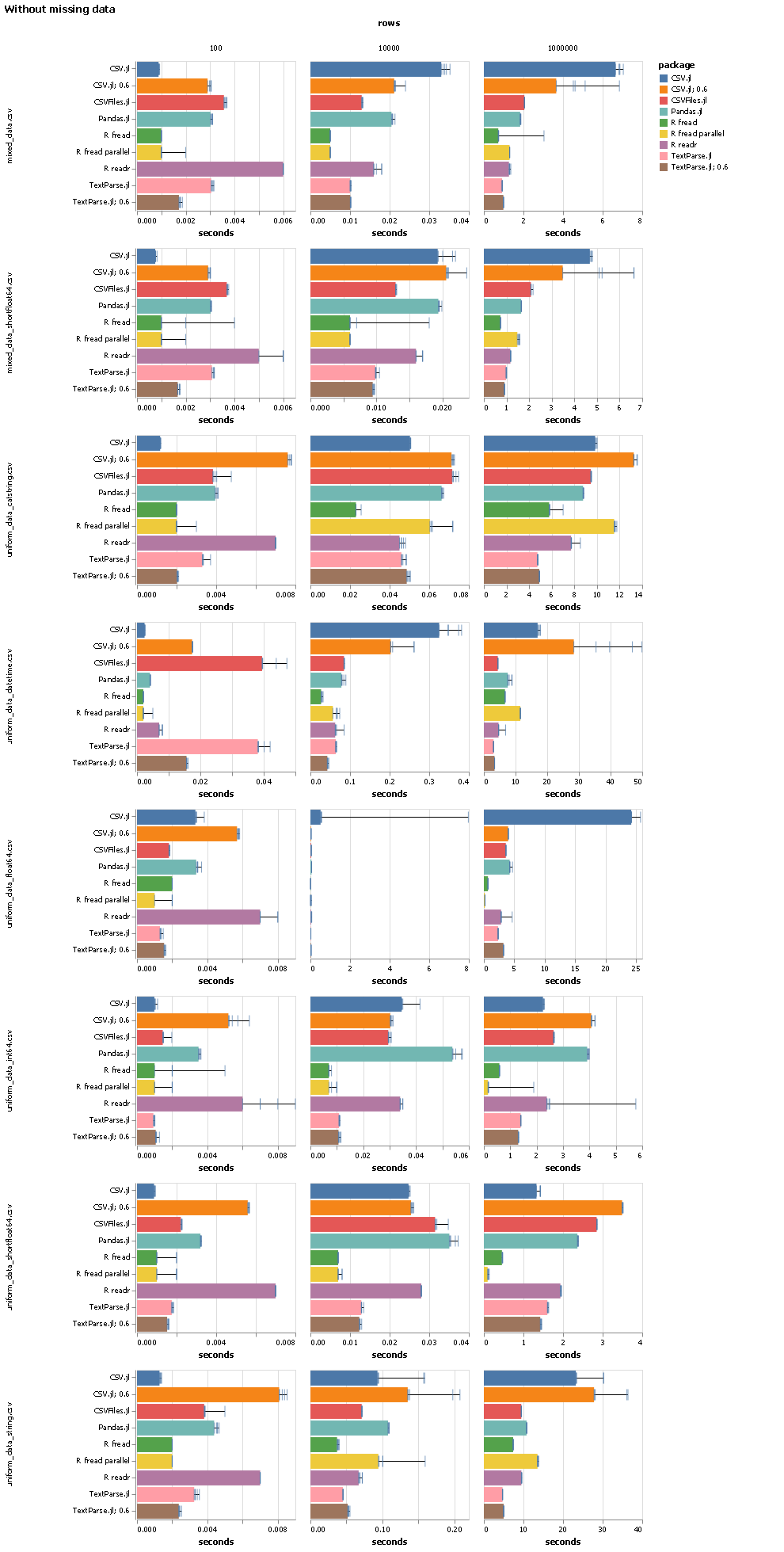
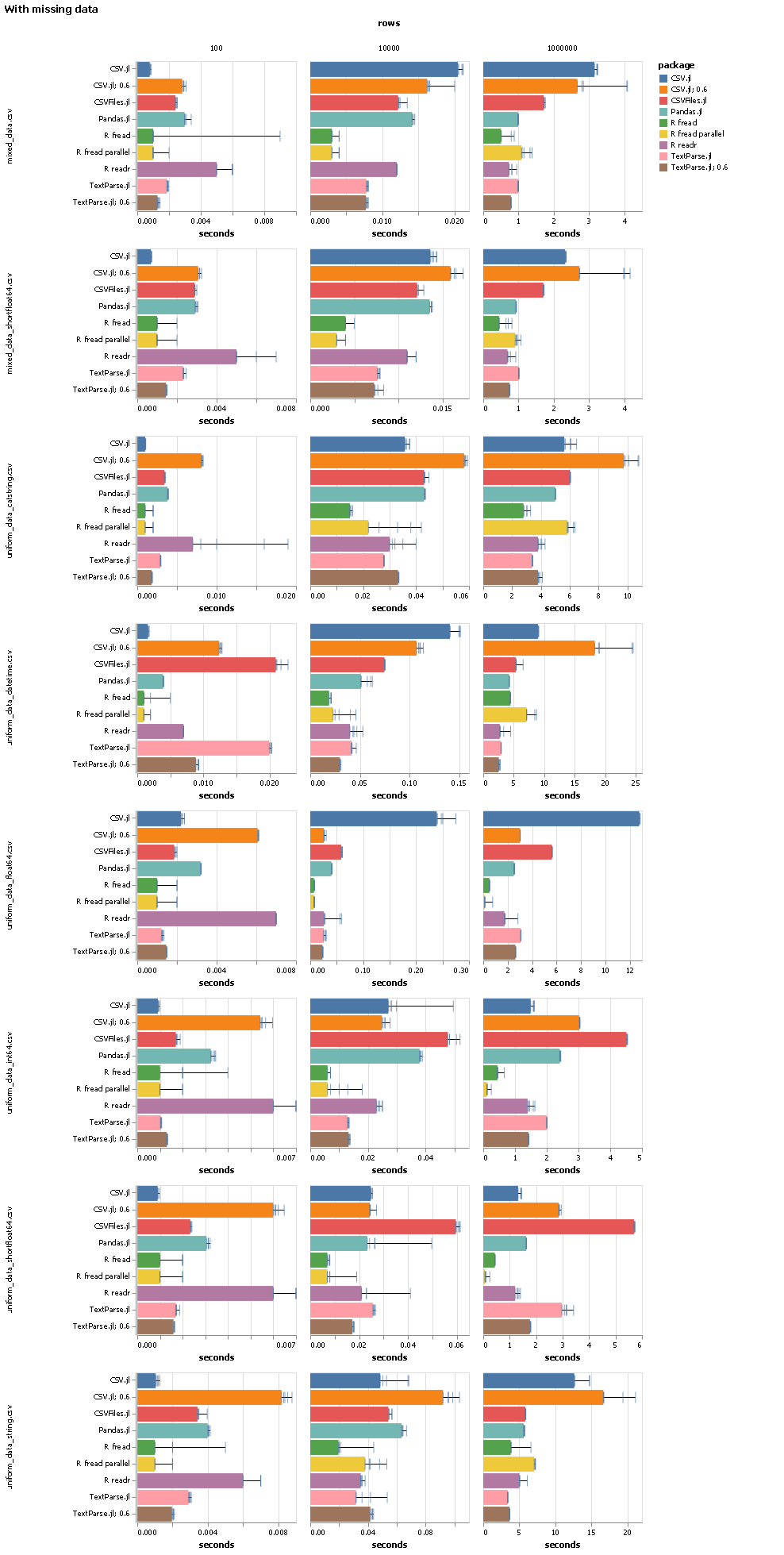
As part of that work I also wrote a benchmark that compares various CSV reading packages on julia, Python and R. The high-level summary is that R’s fread beats pretty much everything, but other than that TextParse.jl is (and was on julia 0.6) looking pretty good.
I used the currently latest tagged version of all packages that are tested. A “; 0.6” in the package name means this run was done on julia 0.6. I ran every benchmark five times. The bar shows the best of those five runs, and all five runs are shown as ticks. The different files have different types of data in the columns: the files with “mixed” in the name have one column of float, int, string, categorical string (a string column that only ever has a few different values) and datetime. The files with “uniform” in the name have 20 columns all with the same data type. “short” in the filename signals that floating point numbers don’t have more than 6 digits.
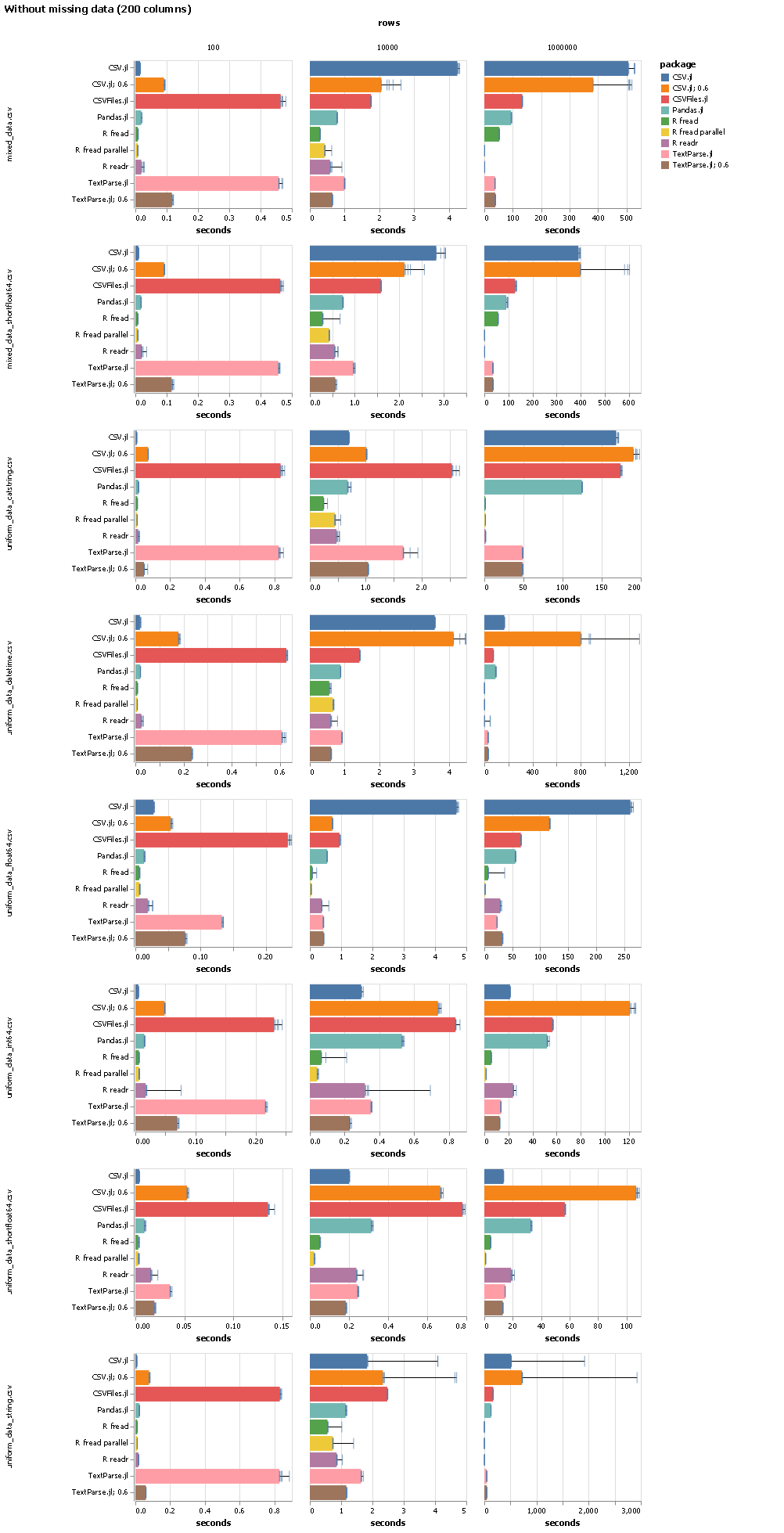
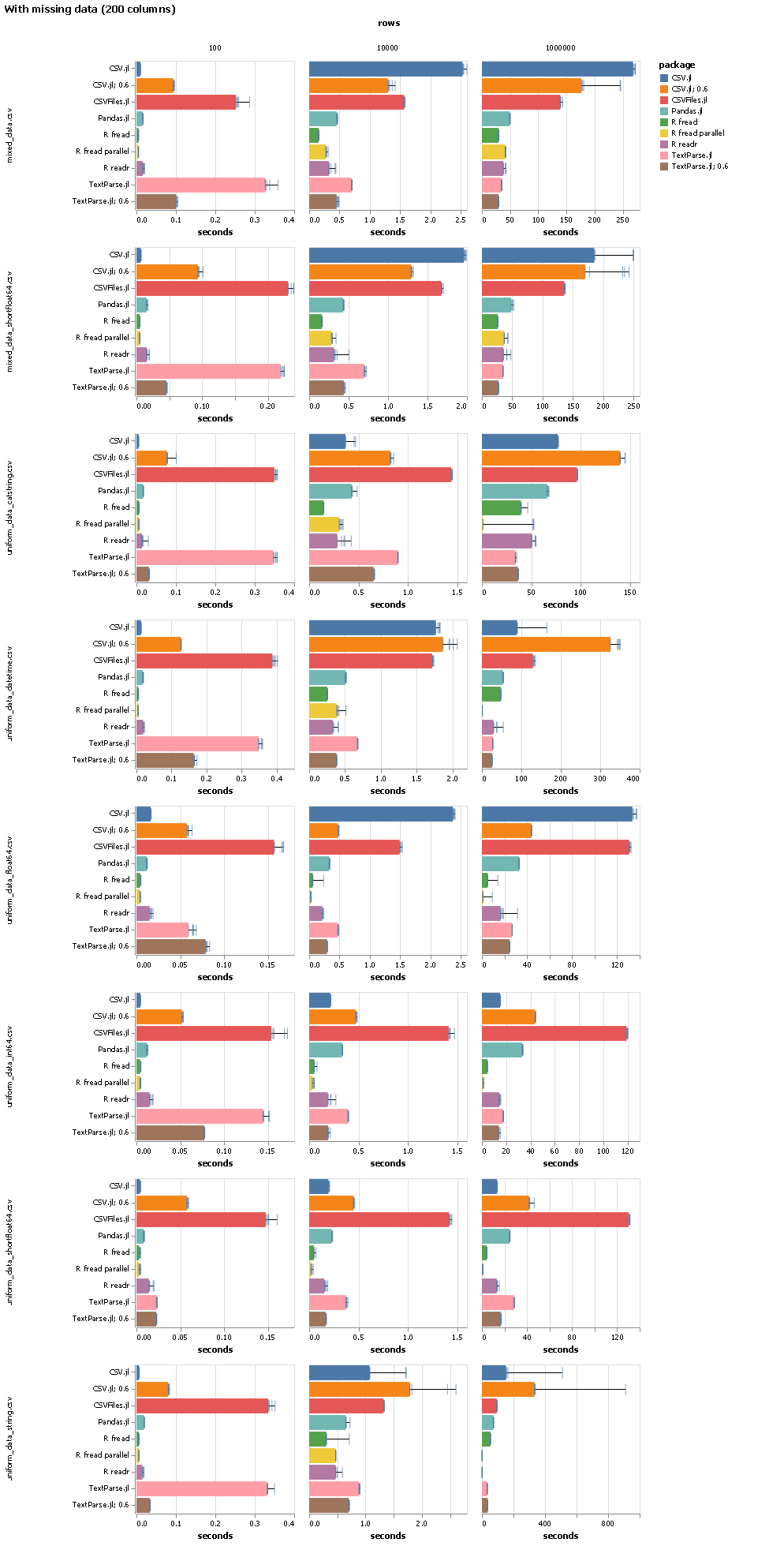
Thanks a lot for your effort and these extensive benchmarks. I was wondering about the number of columns per data set, it would be great to see how each approach scales as a function of that. Last time I checked, most julia solutions (except DataFrame’s deprecated readtable and Base’s readdlm) were struggling with high-dimensional data sets (>1k columns).
There is no theoretical reason it couldn’t, someone just needs to put in the micro-optimization work.
I think that fixing major performance regressions is important, so I am happy that TextParse.jl is competitive again, but I am not sure that it is super-important to beat data.table::fread once we are within 5x. Data reading is usually the least expensive part of a nontrivial computation, and one would not read all the data for large files (when this matters the most) into memory anyway.
And to add to that, TextParse.jl looks already quite comparable to fread for larger numbers of rows. If one has to read many small csv files (which is also an important use case), TextParse.jl may be slower for now, but coincidentally this is where CSV.jl seems to do very well.
Agreed, a PR that adds runs with say 100, 1k and 10k columns would be great!
I entirely agree! My goal with the recent work was not to write the fastest CSV parser, I mainly just wanted to get TextParse.jl back into a usable state, so I did some very targeted optimizations so that it got back to the excellent performance it had on julia 0.6 (thanks to @shashi!). There are actually a lot of places where one could do more, but for now I thought we should release a version that is back to the old performance.
No idea TextParse.jl was just always really fast, I think @shashi just did some awesome work with it. Also keep in mind that CSV.jl (the current version) is really a young package. Even though the package itself has been around for a long time, I believe the current version is essentially a recent complete rewrite. I would guess that this is simply a case where it takes time to mature a package.
Do you have any ideas as to why there seems to be substantial overhead between CSVFiles and TextParse? Sometimes the time difference looks negligible, but typically I see CSVFiles lagging behind, even though it is TextParse under the hood.
I’m curious as well, I saw in one additional high-dimensional test (5K rows, 6K cols) that differences are even more pronounced (TextParse < 5s, pandas < 10s, CSVFiles > 700s). But since TextParse is already there, I think that should be fixable.
Yes, I do I’ve had some PRs lingering around that address that for many, many months. Most of them are merged now. The only thing left to do is to merge this, and then there is no real overhead left from using CSVFiles.jl, i.e. you get the same performance that raw TextParse.jl gives you.




{kind=link}
{kind=link}
{kind=link}
{kind=link}