Loops are just as fast in Julia as they are in Fortran, and a well-written loop is often the single fastest way to implement an algorithm.
What is your code actually supposed to do? Your inner loop over k in 1:p just does the same operation over and over. Removing that loop would obviously speed up your code, but I suspect that isn’t what you want.
Also, have you read the Julia performance tips? That’s the first place to start to learn how to make your Julia code faster.
n=5000
p=5000
m=5000
A=rand(n,p);
B=rand(p,m);
C=zeros(Float64,n,m)
for i in 1:n
for j in 1:m
C[i,j]=0.0
for k in 1:p
C[i,j] = C[i,j]+A[i,j]*B[i,j]
end
end
end
I would add that… are you timing your code as it is shown or do you have it inside a function?
function f()
n=5
p=5
m=5
A=rand(n,p)
B=rand(p,m)
C=zeros(Float64,n,m)
for i in 1:n
for j in 1:m
C[i,j]=0.0
for k in 1:p
C[i,j] = C[i,j]+A[i,j]*B[i,j]
end
end
end
end
@time f()
You should try to switch the order of the loops. In Julia matrices are stored column-major, which means that to access A[i,j] linearly in memory (which is fastest), i be the variable that changes fastest.
Therefore, instead of
for i in 1:n
for j in 1:m
C[i,j]=0.0
....
end
end
try this:
for j in 1:m
for i in 1:n
C[i,j]=0.0
....
end
end
(the only change is that i is traversed in the inner loop now).
function f(n,p,m)
A=rand(n,p)
B=rand(p,m)
C=zeros(Float64,n,m)
for i in 1:n
for j in 1:m
C[i,j]=0.0
for k in 1:p
C[i,j] = C[i,j]+A[i,j]*B[i,j]
end
end
end
end
julia> @time f(1000,1000,1000)
1.756890 seconds (10 allocations: 22.889 MiB, 2.62% gc time)
julia> @time f(2000,2000,2000)
27.841935 seconds (10 allocations: 91.553 MiB, 0.36% gc time)
julia> @time f(5000,5000,5000)
429.574190 seconds (10 allocations: 572.205 MiB, 0.02% gc time)
You also want to try multithreading. Just adding Threads.@threads to the outermost loop significantly improved performance.
function f2(n,p,m)
A=rand(n,p)
B=rand(p,m)
C=zeros(Float64,n,m)
Threads.@threads for j in 1:m
for i in 1:n
C[i,j]=0.0
for k in 1:p
C[i,j] = C[i,j]+A[i,j]*B[i,j]
end
end
end
end
julia> @time f2(5000,5000,5000); # with JULIA_NUM_THREADS=12
52.803032 seconds (11 allocations: 572.205 MiB, 0.21% gc time)
F.Y.I. You need to set the environmental variable JULIA_NUM_THREADS before you start julia
Even without multithreading if you avoid going to the arrays 125 billion times, you can improve the performance a lot
function f3(n,p,m)
A=rand(n,p)
B=rand(p,m)
C=zeros(Float64,n,m)
for i in 1:n
for j in 1:m
aux=0.0
A_i_j = A[i,j]
B_i_j = B[i,j]
for k in 1:p
aux += A_i_j *B_i_j
end
C[i,j]=aux
end
end
end
However, the toy example is starting to wear out its usefulness. There is nothing faster than loops since loops are just a way of jumping back to an earlier instruction. Instead one should talk about the operation that should be performed and how that can be done as efficiently as possible.
function f3(n,p,m)
A=rand(n,p)
B=rand(p,m)
C=zeros(Float64,n,m)
@inbounds for i in 1:n
for j in 1:m
aux=0.0
A_i_j = A[i,j]
B_i_j = B[i,j]
@simd for k in 1:p
aux += A_i_j *B_i_j
end
C[i,j]=aux
end
end
end
Remember that you can get a nice speed boost if you don’t need Float64 (going down to 7 sec in Float32). Even bigger if your CPU has AVX512.
function f5(n,p,m)
A=rand(Float32, n,p)
B=rand(Float32, p,m)
C=zeros(Float32, n,m)
@inbounds for i in 1:n
for j in 1:m
aux=Float32(0.0)
A_i_j = A[i,j]
B_i_j = B[i,j]
@simd for k in 1:p
aux += A_i_j *B_i_j
end
C[i,j]=aux
end
end
end
@time f5(5000,5000,5000)
7.271317 seconds (10 allocations: 286.103 MiB, 1.38% gc time)
knowing what multiplication means is indeed useful. I guess the question was about how to use “julia syntax” not how to “rethink” the code to go from O(n^3) to O(n^2).
In that case, @Aquaman:
Just use the BLAS library; it will be many times faster than the loops.
# If C has not already been allocated
C = A * B
# If you pre-allocated C
using LinearAlgebra
mul!(C, A, B)
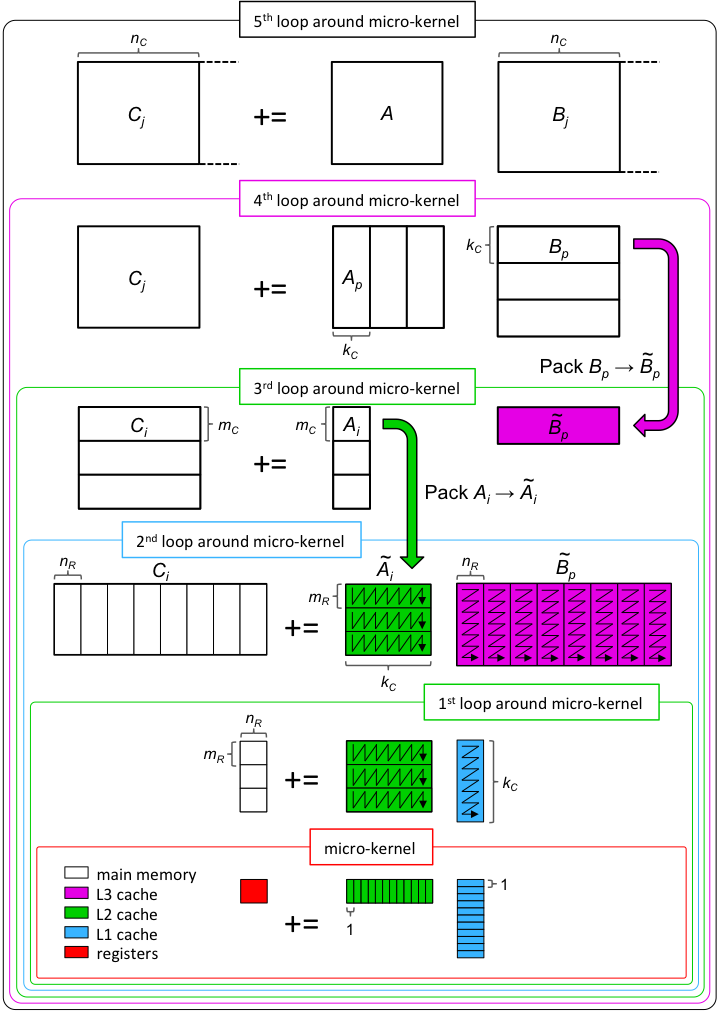
The BLAS libraries also use loops – but there are actually five of them, not three!*
They loop over an optimized microkernel. The optimized kernel is architecture dependent, so OpenBLAS (and other optimized BLAS libraries) will choose the correct one based on your CPU.
They’re also multithreaded.
*Although two of the loops are probably going to be completely unrolled.
{kind=link}