Hello Julia Community, especially Dagger and HPC developers. I hope you are doing well this summer and have achieved your goals! I’m here to share:
- Dagger’s MPI Implementation status
- My Google Summer of Code at Julia conclusion
- Some great data visualization about Dagger’s MPI Implementation
I would like to express my heartfelt gratitude for the incredible mentorship and support that @fda-tome and @jpsamaroo provided me during this summer. Their support enabled me to work at MIT CSAIL in the Julia Lab, which was a wonderful experience. I also had the pleasure of meeting @evelyne-ringoot and @rayegun, who welcomed me warmly. I truly appreciated the opportunity to work with the Julia language.
A Few Things I Forgot to Mention
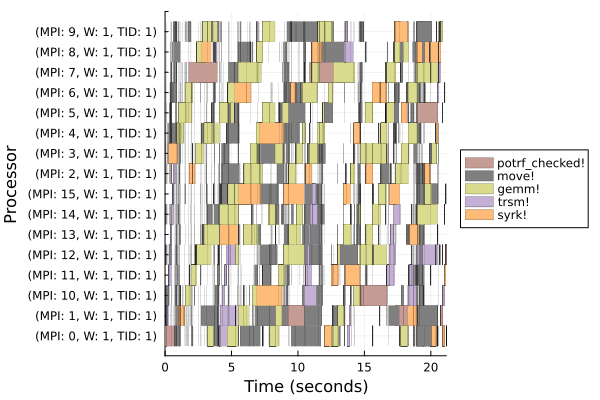
In my previous update Faster MPI Integration in Dagger, I mentioned the core functionality of our MPI implementation. I want to add that the communication layer is built on nonblocking MPI with cooperative progress. This allows asynchronous sends and receives to be polled while yielding, which naturally overlaps computation with communication and lets other Julia tasks run simultaneously.
The ultimate goal of this project is to extend Dagger’s capabilities to HPC clusters with low-latency interconnects, as its default TCP communication is a limiting factor in these environments. The core of our solution is Dagger’s MPI Implementation, which replaces the TCP transport with MPI-aware task placement and data movement.
Benchmark setup
The performance of Dagger’s MPI Implementation was evaluated against Dagger’s TCP backend using Cholesky decomposition as a parallel benchmark. The experiments were conducted on a high-memory cloud instance (AWS r5d.24xlarge featuring 96 CPUs and 768 GB of RAM).
Evaluation
Two types of scaling experiments were performed to evaluate the system’s performance closely:
- Strong scaling examined the performance of a fixed 18000 x 18000 matrix workload distributed across multiple processors, aimed at testing the framework’s ability to allocate a constant workload among the cores.
- Weak scaling analyzed performance with a workload that increased in size proportionally to the number of processors, varying from 1 to 81, to gain insight into how performance evolved as both the workload and computing capacity expanded concurrently.
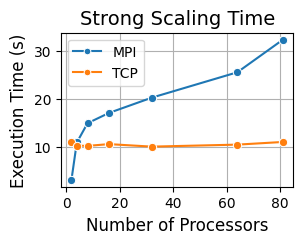

Figure 1: Strong and weak scaling execution times versus the number of processors with MPI and TCP backends using Float32 data type.
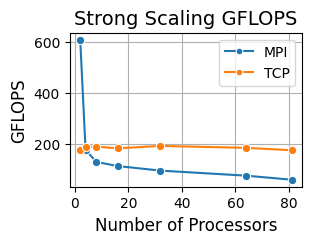

Figure 2: Strong and weak scaling GFLOPS versus the number of processors with MPI and TCP backends using Float32 data type.
Our evaluation, summarized in Figures 1 and 2, provides an initial view of the performance trade-offs between MPI and TCP backends. In execution time Figure 1, MPI achieves lower runtimes at small to medium process counts but degrades as communication overheads grow, while TCP remains nearly constant, reflecting its lack of distributed scaling. In strong scaling Figure 2, MPI initially sustains higher throughput at 2 processors, but efficiency decreases rapidly as process counts grow, while TCP remains more stable. The initial results, however, successfully demonstrate Dagger’s ability to leverage HPC interconnects for parallel workloads.
Next Steps and How to Contribute
We are still working to fully optimize the MPI implementation to unlock its full potential. Unfortunately, we couldn’t complete the RMA implementation for broadcasting, as we focused on establishing a solid benchmark setup to gather data for our ACM SC25 poster. We are eagerly awaiting the results!
Moving forward, I’ll continue to work on the RMA implementation and profile our MPI code to identify and reduce communication overhead.
If you’d like to contribute, you can find the implementation in the yg/faster-mpi branch. We are cleaning up the code to get it ready for merging. Feel free to dive into the Dagger documentation and explore our MPI code, especially the point-to-point and broadcast communication implementations. Any issues or pull requests are welcome on the Dagger repository on GitHub.