Another interesting observation. Using the following code:
using BenchmarkTools
using KernelAbstractions
func1(a, b) = a * b
func2(a, b) = exp(a) * sin(b)
function mulcab!(C, A, B)
N1, N2 = size(C)
for j=1:N2, i=1:N1
C[i,j] = func2(A[i,j], B[i,j])
end
return nothing
end
@kernel function mulcab_kernel(C, A, B)
i, j = @index(Global, NTuple)
@inbounds C[i,j] = func2(A[i,j], B[i,j])
end
function mulcab_ka!(C, A, B)
backend = get_backend(C)
ndrange = size(C)
mulcab_kernel(backend)(C, A, B; ndrange)
return nothing
end
N = 2048 # 2 - 8192
A = 2 * ones(N, N)
B = 3 * ones(N, N)
C = zeros(N, N)
@btime mulcab!($C, $A, $B)
@btime mulcab_ka!($C, $A, $B)
I measured the computation times of simple loop and the corresponding KA kernel versus the size of the input array. I considered two cases: 1) low cost (func1(a, b) = a * b) and high cost (func2(a, b) = exp(a) * sin(b)) kernel function. The figures below show the resulting run time vs log2(N).

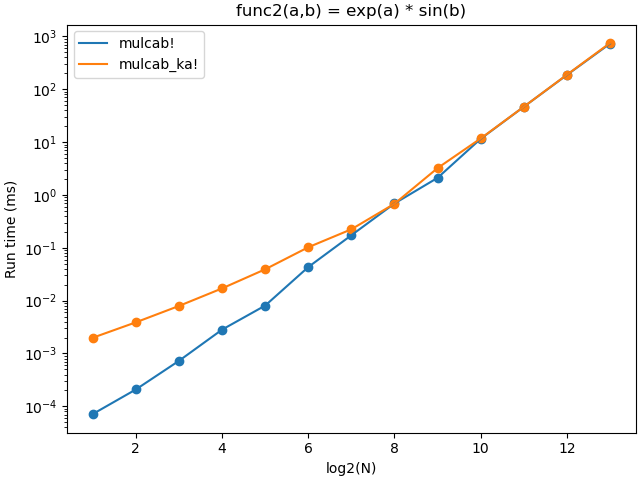
The figures show that KA introduce quite high overhead. For simple (memory bound) kernel, the overhead time becomes negligible starting from array sizes 1024x1024, while for more costly kernel, the corresponding array size is 128x128.
I guess, the conclusions can be the following. At present time KA introduce unpleasantly high overhead. Therefore, the recommendation is to combine small kernels into one big with high computational costs.


