For example, let’s say I create a set:
A = {1,2,3,4,5}
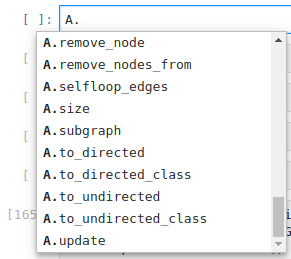
Now suppose I want to take one element off. Even without consulting the documentation, even if I’ve never used a set in Python before, I know that I can probably find what I need by just hitting A.<tab> and Jupyter will suggest all the useful things I might want to do with a set:

There are a very reasonable number of items to search through, and from this alone it is clear that what I want is A.pop(). Of course, features which are used often from the standard library become familiar with time, but for third-party packages this discoverability is paramount. For example, using the graph package networkx, I barely had to consult the documentation to figure out how to use it. Here’s a version of how my thought process went:
“Great, looks like networkx can do graphs! Let’s import it.”

“Hmm, how to create a graph? Maybe there is a Graph constructor…”

“Perfect! Now, let’s see, do I need to pass it anything?”
“Looks like it’s optional. Quick peek at the examples…”
“OK, so I can create an empty graph and add nodes. Let’s start there…”
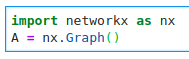
“OK, now how did I add a node? Was it
add_node or
addnode or
addNode? Let’s check…”

“Oh sweet, look at all this stuff I can do! I was going to add nodes one at a time but it looks like I can pass a whole list…”
“Yup, nice! Now how would I go about converting this to a directed graph?”
(and so on)
The point is that this was very easy and quick to discover and explore the functionality without consulting the documentation.
With Julia, a side-effect of multi-dispatch is that I never know what functions are intended to apply to a given object. If I make create a set and I don’t remember how to grab an element from it I have to search through the documentation. Even then, there isn’t a section which seems to list “common things you might want to do with sets”, since many of the things you do with sets (count their elements, retrieve a single element) are also done by anything which is a collection, so discoverability has been a challenge.
With third-party packages, this is even worse! With enough use, elements of the standard library will become familiar, however what happens when I try to use the Julia graph package without consulting the documentation? If I want to, I can import the package and look at everything it provides,
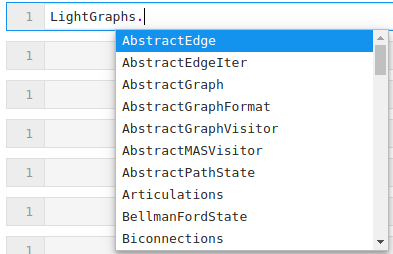
but this list is huge and I am not going to learn much by searching through it. Applying my previous workflow, I might try this:
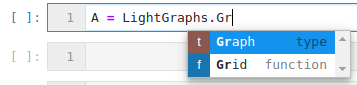
“OK, so do I need to pass it anything?”

“Hmm… OK, not sure. That may be a documentation issue, although simply having some constructor heading would be helpful… Let’s try it anyway.”

“Hmm… OK, that’s not helpful. How can I add nodes to this? Maybe there is an add_nodes function like in python?”

(hitting <tab>, nothing happens)
“Hmm… So I guess I can either look through all the functions available from LightGraphs or I have to just guess at the name. Maybe it starts with add…”
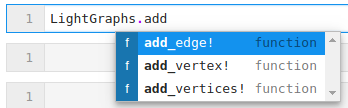
“OK, add_vertices! looks promising! Now how would I go about converting this to a directed graph… Hmmm… Guess I should search the docs or look at the source code…”










