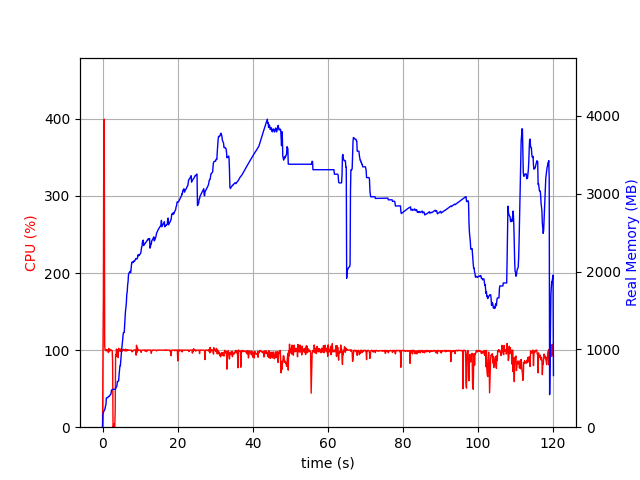
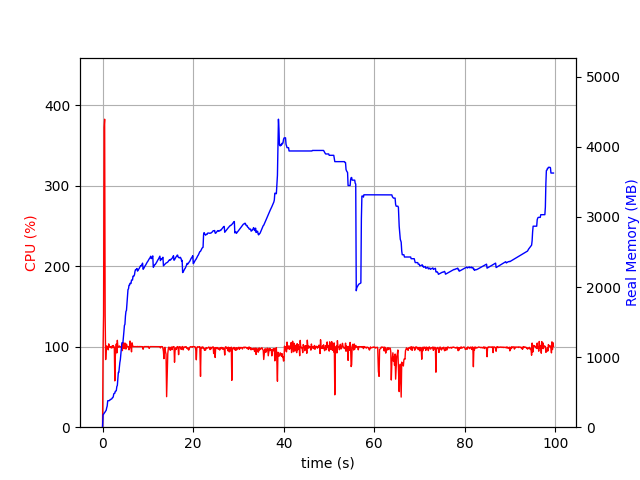
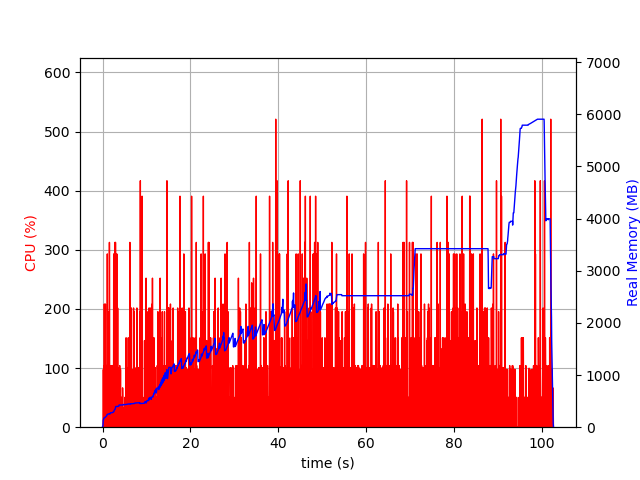
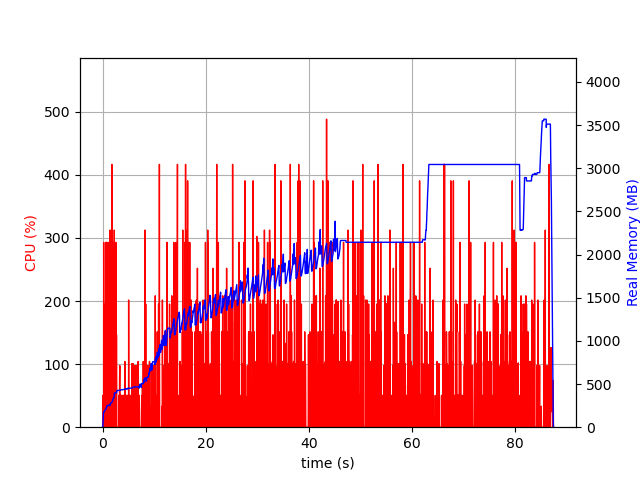
Thank you for your explanation. I did not now of the psrecond and recording file, which really helped me to solve the issue, thanks!
After fixing the typo in the constraint, JuMP still used way more memory compared to the C API.
The JuMP variant still had additional presolve steps, which caused the higher memory consumption (as you also indicated). The difference between the two models were the variable bounds (as could also be observed from the ‘Bound range’ in the logfiles). Adding a variable with @variable(model, binary = true) results in a lower bound -infinity and upper bound +infinity. However, adding a binary variable with GRBaddvar(model, 0, Cint[], Cdouble[], 0.0, 0, GRB_INFINITY, GRB_BINARY, C_NULL) results in a lower bound of 0 and upper bound of 1.
Changing from @variable(model, binary = true) to @variable(model, binary = true, lower_bound=0, upper_bound=1) results in the same variable bounds for JuMP and the C API, and therefore the presolve step for the JuMP API does no longer occur. Then, there is only limited memory overhead for JuMP (15%).
The only difference is how the model is build, as the recording file has the additional lines:
*Replay* Change 5000000 variable bounds
---
*Replay* Change 2500000 variable types
*Replay* Update Gurobi model
*Replay* Update Gurobi model
So apparently, most memory consumption was due to Gurobi’s presolve and not JuMP itself. Adding variables with JuMP is slower, but only introduces limited memory overhead. And using @variable(model, binary = true, lower_bound=0, upper_bound=1) instead of @variable(model, binary = true) result in a model that is similar as when you would directly use the C API.
Thanks for the help!
using StatsBase
using JuMP
using Gurobi
using MathOptInterface
using Random
function obtain_new_columns(num_nodes, num_routes)
new_columns= Vector{Vector{Int64}}()
for i=1:num_routes
route= sample(1:num_nodes, 20; replace= false)
push!(new_columns, route)
end
return new_columns
end
function model_jump(routes, num_nodes)
env = Gurobi.Env(Dict{String, Any}("Record" => 1,))
model = direct_model(Gurobi.Optimizer(env))
set_string_names_on_creation(model, false)
x= Vector{VariableRef}()
@constraint(model, constr[i=1:num_nodes], 0 <= 1)
for route in routes
push!(x, @variable(model, binary=true, lower_bound= 0, upper_bound= 1.0))
#push!(x, @variable(model, binary=true))
set_objective_coefficient(model, x[end], 1)
for i in route
set_normalized_coefficient(constr[i], x[end], 1)
end
end
@constraint(model, sum(x) <= 0)
#error = GRBwrite(backend(model), "jump2.lp")
#error = GRBwrite(backend(model), "jump2.mps")
optimize!(model)
return MOI.get(model, Gurobi.ModelAttribute("MemUsed")), MOI.get(model, Gurobi.ModelAttribute("MaxMemUsed"))
end
function model_api(routes, num_nodes)
env_p= Ref{Ptr{Cvoid}}()
error = Gurobi.GRBemptyenv(env_p)
env= env_p[]
error = GRBsetintparam(env, "Record", 1)
error= GRBstartenv(env)
model_p = Ref{Ptr{Cvoid}}()
error= GRBnewmodel(env, model_p, "test", 0, C_NULL, C_NULL, C_NULL, C_NULL, C_NULL)
model = model_p[]
for i=1:num_nodes
rhs=1.0
error= GRBaddconstr(model, 0, Cint[], Cdouble[], GRB_LESS_EQUAL, rhs, C_NULL)
end
#=
for (i,route) in enumerate(routes)
ind= Cint[(route .-1)...]
val= Cdouble[1 for i=1:length(route)]
nzc = length(ind)
error = GRBaddvar(model, nzc, ind, val, 1.0, 0.0, 1.0, GRB_BINARY, C_NULL)
end
=#
for (i,route) in enumerate(routes)
#GRBaddvar(model, 0, Cint[], Cdouble[], 0.0, 0.0, 1.0, GRB_BINARY, C_NULL)
#GRBaddvar(model, 0, Cint[], Cdouble[], 0.0, -GRB_INFINITY, GRB_INFINITY, GRB_BINARY, C_NULL)
GRBaddvar(model, 0, Cint[], Cdouble[], 0.0, 0.0, GRB_INFINITY, GRB_BINARY, C_NULL)
error = GRBsetdblattrelement(model, "Obj", i-1, 1.0)
for j in route
ind= Cint[j-1]
var= Cint[i-1]
val= Cdouble[1]
nzc= length(ind)
error= GRBchgcoeffs(model, nzc, ind, var, val)
end
end
error= GRBaddconstr(model, length(routes), Cint[i for i=0:length(routes)], Cdouble[1.0 for i=1:length(routes)], GRB_LESS_EQUAL, 0.0, C_NULL)
#error = GRBwrite(model, "api.lp")
#error = GRBwrite(model, "api.mps")
error = GRBoptimize(model)
mem_used= Ref{Cdouble}()
error= GRBgetdblattr(model, "MemUsed", mem_used)
mem_used = mem_used[]
max_mem_used= Ref{Cdouble}()
error= GRBgetdblattr(model, "MaxMemUsed", max_mem_used)
max_mem_used = max_mem_used[]
return mem_used, max_mem_used
end
Random.seed!(1234)
num_nodes= 100
# compile
routes= obtain_new_columns(num_nodes, 100)
@time mem_used_jump, max_mem_used_jump= model_jump(routes, num_nodes)
@time mem_used_api, max_mem_used_api= model_api(routes, num_nodes)
# test
routes= obtain_new_columns(num_nodes, 2500000)
@time mem_used_jump, max_mem_used_jump= model_jump(routes, num_nodes)
println("Jump: Memory used: ", mem_used_jump, " GB, Max memory used: ", max_mem_used_jump, " GB")
@time mem_used_api, max_mem_used_api= model_api(routes, num_nodes)
println("API: Memory used: ", mem_used_api, " GB, Max memory used: ", max_mem_used_api, " GB")
102.146279 seconds (270.00 M allocations: 5.788 GiB, 2.49% gc time)
Jump: Memory used: 2.603016821 GB, Max memory used: 2.733017629 GB
73.547856 seconds (155.00 M allocations: 9.267 GiB, 3.76% gc time)
API: Memory used: 2.536407267 GB, Max memory used: 2.666408075 GB