What is the correct way of using MKL.jl on Julia Version 1.7.0-beta3.0 (2021-07-07) wrt the number of distributed processes and multithreading?
I do reinforcement learning (AlphaZero.jl) training on Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz (this is 6 physical cores per socket with 2 sockets which means 12 physical and 24 logical cores).
I was able to use MKL.jl without any problems when starting julia -t 12 and not using distributed processing, however the calculations were rather very slow. I saw %Cpu(s) at about 54.8 us, %CPU was about 2144% and RAM utilization was very low in comparison to some of my fastest distributed calculations.
When doing tries with Distributed, addprocs(12) I encountered several problems mostly related to:
From worker 8: OMP: Error #34: System unable to allocate necessary resources for OMP thread:
From worker 8: OMP: System error #11: Resource temporarily unavailable
From worker 8: OMP: Hint: Try decreasing the value of OMP_NUM_THREADS.
Thus I would like to ask for an advice.
How should I start julia?
julia -t 12 or
julia -t 24 or
julia
or maybe
julia -p 12 -t 12 or
julia -p 24 -t 24
How many distributed processes should I add?
using Distributed; addprocs(12)
using Distributed; addprocs(24)
none
How should I be using MKL?
using MKL
@everywhere using MKL
How many BLAS threads should I be setting?
BLAS.set_num_threads(12)
BLAS.set_num_threads(24) [AFAIK MKL is operating on physical cores so this should be rather incorrect]
BLAS.set_num_threads(1)
How should I be using LinearAlgebra?
using LinearAlgebra
@everywhere using LinearAlgebra
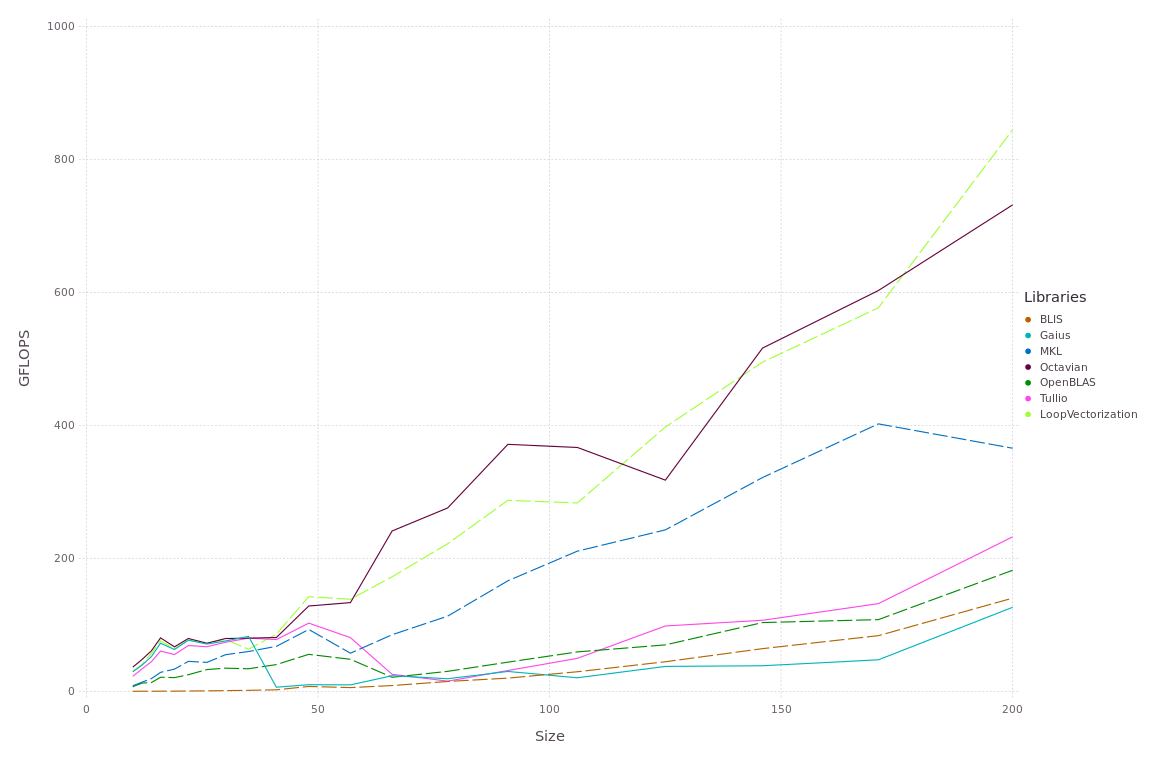
I would like to take maximum advantage of all of the FLOPS on the machine. I would appreciate some advice / information on this topic, even some hints would be appreciated. Below I am enclosing BLASBenchmarksCPU.jl charts if this might be of any use [julia started as julia -t 24].
FWIW, I have no problems with MKL on Julia 1.7 or master, and use Distributed.jl.
For clarification, are you calling MKL in parallel?
If your Julia code is parallel, I’d restrrict MKL to 1 thread, e.g. I’d start julia with
OMP_NUM_THREADS=1 julia -p12 -t1
and then
@everywhere begin
using LinearAlgebra, MKL
BLAS.set_num_threads(1)
end
However, if you have single threaded Julia code calling expensive BLAS operations, you can set BLAS.set_num_threads(12).
FWIW, BLASBenchmarksCPU will set MKL to use min(num_cores(), Threads.nthreads()) threads. So if you start Julia with >= 12 threads, it’ll tell MKL to use 12.
Normally MKL is pretty smart about choosing the number of threads on its own. Some other libraries (OpenBLAS, BLIS) are not.
However, if you’re calling MKL from different threads in parallel, you should restrict MKL to 1.
I cannot add anything here - however this is a very interesting thread for me.
One thing to add - I know hyperthreading has changed as CPUs have developed.
However the mantra in HPC is always ‘hyperthreading should be switched off’
I would love to see a comparison here with HT on/off - genuinely curious as I do not think that mantra holds true every time.
For clarification, are you calling MKL in parallel?
I am not the author of the code (AlphaZero.jl) and I have to admit that I do not understand it in full detail. My current understanding is that the first phase (so called self play) is parallel in full. As for the next phases, I think the same, however, according to the best of my knowledge, I was not able to achieve full CPU utilization (I also tried your first suggestion and a derivative of the second). What I would like to underline is that I do not have extensive experience in this area. If this is to your interest please take a look at AlphaZero.jl by yourself. I also tried to provide as detailed info as possible in “Questions on parallelization #71” thread (hope its all correct there, however, I was not expecting such detailed discussion and my notes from the trainings were rather short). This is really interesting program and I enjoyed the time spent with it. I was also really happy to use it with CPUs.
One thing to add - I know hyperthreading has changed as CPUs have developed.
However the mantra in HPC is always ‘hyperthreading should be switched off’
I would love to see a comparison here with HT on/off - genuinely curious as I do not think that mantra holds true every time.
I would be happy to do the tests, however, please be informed that it seems to be quite time consuming and/or resource intensive process. Especially for the CPUs and AlphaZero. There might be some info to your interest included in the above mentioned “Questions on parallelization #71” thread, however, I would rather not call it a test.