Consider a routine continuous time optimization problem from economics:
V(t,a_{t}) :=
\max \int_{\tau=t}^{\tau = T}
e^{-\rho (\tau -t)} u(c_{\tau})d\tau
\text{ s.t. }
\dot{a}_{t} = y + ra_{t} - c_{t},
a_{0} \text{ given, } a_{T}=0.
Assume y & r are constants and u(c)=\frac{c^{1-\gamma}}{1-\gamma}.
The problem has a known closed form solution:

Here I plot V(0,a_{t}) and V(t,1):

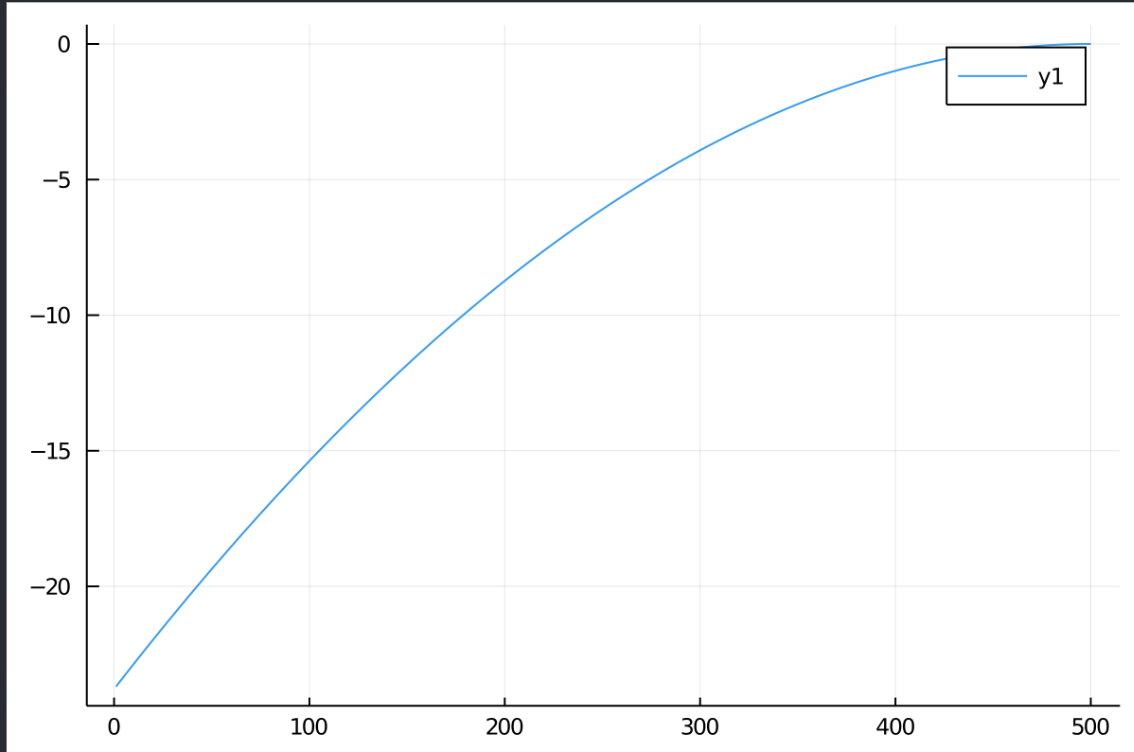
To solve this using the HJB approach requires solving a PDE:
\left[\begin{array}{l}
\rho V(t,a_{t}) = \frac{c_{t}^{1-\gamma}}{1-\gamma} +
V_{a}(t,a_{t})\times \left(y + ra_{t} - c_{t} \right) + V_{t}(t,a_{t})
\\
c(t,a_{t}) = (V_{a}(t,a_{t}))^{-\frac{1}{\gamma}}
\\
V(T,a_{T}) = 0
\end{array} \right]
I’m trying to solve it w/ ModelingToolkit.jl, but it’s taking forever & not converging.
using NeuralPDE, Flux, ModelingToolkit, GalacticOptim, Optim, DiffEqFlux
using Plots
@parameters t a θ
@variables V(..)
@derivatives Da'~a
@derivatives Dt'~t
#
u(c,γ)= (c^(1.0 -γ))/(1.0 -γ);
γ = 2.00; ρ = 0.01; r = 0.01; y = 0.00; T = 5.0;
ω = r - (r-ρ)/γ;
# Closed form solution.
VS(t,a;y=y,r=r,γ=γ,ω=ω,T=T)=
u(a+(y/r), γ) * ( (1.0 - exp(-ω*(T-t))) / ω )^γ;
# if r=ρ
CS(t,a;y=y,r=r,γ=γ,ω=ω,T=T, a0=1) = (r*a0)/(1.0 - exp(-r*T) )
AS(t,a;y=y,r=r,γ=γ,ω=ω,T=T, a0=1) =
(a0)/(1.0 - exp(-r*T) ) +
a0*(1.0 - 1.0/(1.0 - exp(-r*T) ) ) * exp(r*t);
plot( VS.(0.0,0.01:.01:5.0) )
plot( VS.(0.0:.01:5.0,1.0) )
#
v = V(t,a,θ);
va = max(eps(), Da(V(t,a,θ)) );
vt = Dt(V(t,a,θ));
c = (va)^(-1.0/γ);
#uc = u(c,γ)
uc = (va^(1.0 - 1.0/γ) )/(1.0 - γ);
# HJB
eq = ρ*v ~ uc + va*(y + r*a - c) + vt;
# Boundary conditions
bcs = [V(T,a,θ) ~ 0.0] #0.f0
# Space and time domains
domains = [t ∈ IntervalDomain(0.0,5.0),
a ∈ IntervalDomain(0.0,5.0)]
# Discretization
dx = 0.1
# Neural network
dim = 2 # number of dimensions
chain = FastChain(FastDense(dim,16,Flux.σ),FastDense(16,16,Flux.σ),FastDense(16,1))
discretization = PhysicsInformedNN(dx,chain)
pde_system = PDESystem(eq,bcs,domains,[t,a],[V])
prob = discretize(pde_system,discretization)
cb = function (p,l)
println("Current loss is: $l")
return false
end
res = GalacticOptim.solve(prob, Flux.ADAM(); cb = cb, maxiters=10)
res = GalacticOptim.solve(prob, Optim.BFGS(); cb = cb, maxiters=10)
#
phi = discretization.phi
ts,as = [domain.domain.lower:dx/10:domain.domain.upper for domain in domains]
u_predict = reshape(
[first(phi([t,a],res.minimizer)) for t in ts for a in as],
(length(ts),length(as))
)
# plot V(t=0,a) #u_predict[1,:]
plot(as, u_predict[1,:])
# plot V(t, a=0.01)
plot(ts, u_predict[:,1])
- it takes forever & is not accurate
- originally I plugged in the exact equation but got an error
ERROR: DomainError with -0.05701087375174788:
Exponentiation yielding a complex result requires a complex argument.
Replace x^y with (x+0im)^y, Complex(x)^y, or similar.
- the issue is the pde has terms like V_{a}(t,a_{t})^{-\frac{1}{\gamma}} and we have numerical problems related to dividing by zero or taking the root of negative numbers.
We would like to use the prior knowledge that V_{a}>0. - following a suggestion @matthieu , I tried
max(eps(), va)^(-1/γ)
No more domain error, but it takes forever & is not accurate.
Note: if \gamma >1 the trivial solution V(t,a_{t})=0 also satisfies the PDE.
It can be avoided w/ a bequest motive…