I’m loving all the examples being presented here. I would like to encourage folks to submit as many different kinds of examples as possible, and I’ll work on collecting them and getting them onto julialang.org and generally on to social media with something like a #WhyJulia or #WorldOfJulia tag. I think @jiahao used to maintain such a thing a while ago for presentations and such.
It would greatly help to have a 3-5 line description of what it is doing, and why it is interesting, to go along with the code snippet.
-viral




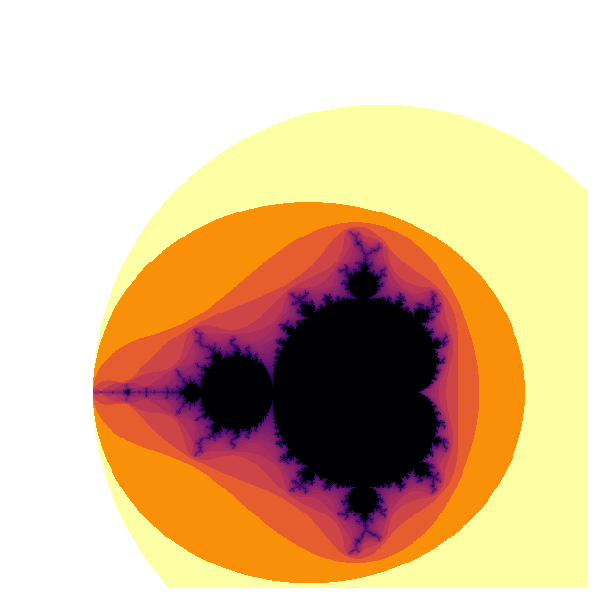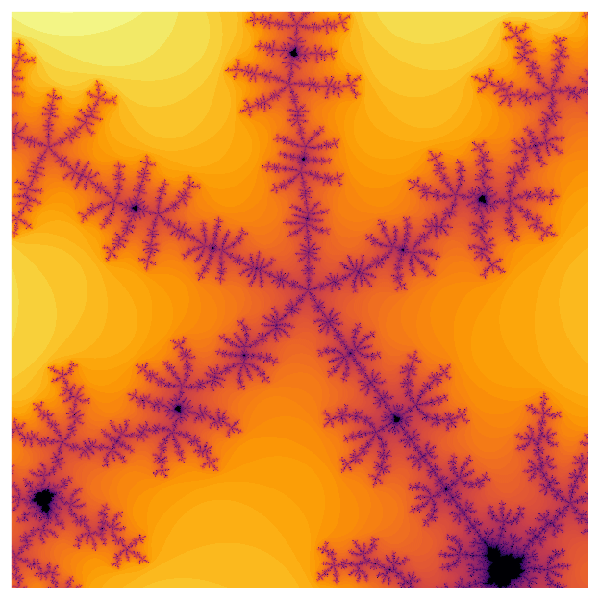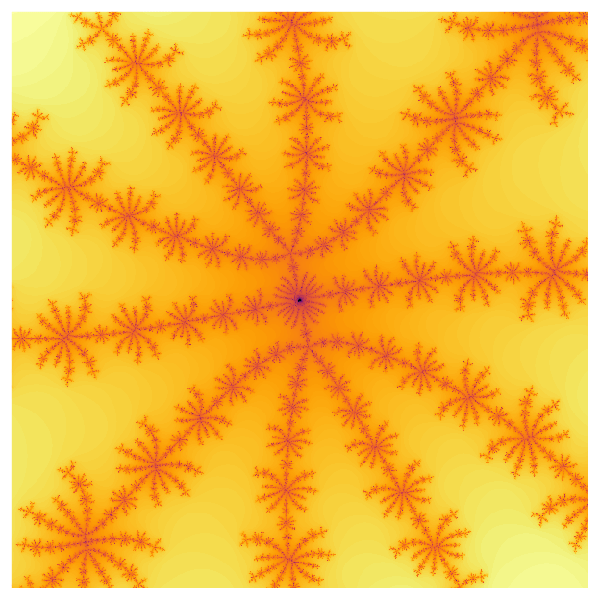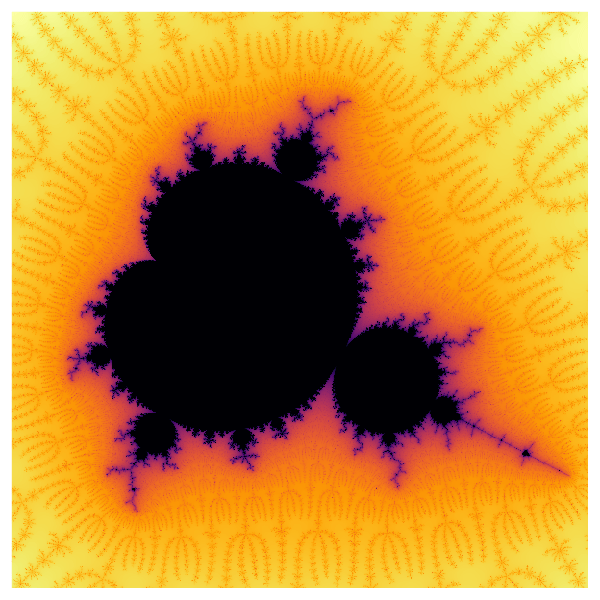{kind=link}