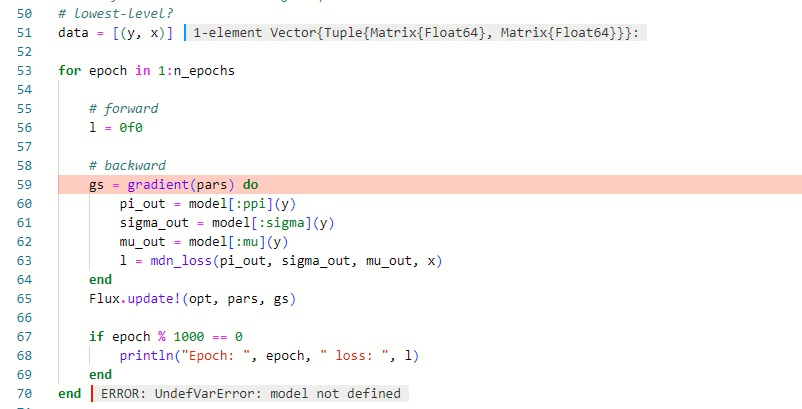
this is the code:
#https://www.janisklaise.com/post/mdn_julia/
using Distributions
using Flux
using Plots
using Random
Random.seed!(12345); # for reproducibility
function generate_data(n_samples)
ϵ = rand(Normal(), 1, n_samples)
x = rand(Uniform(-10.5, 10.5), 1, n_samples)
y = 7sin.(0.75x) + 0.5x + ϵ
return x, y
end
n_samples = 1000
x, y = generate_data(n_samples); # semicolon to suppress output as in MATLAB
scatter(transpose(y), transpose(x), alpha=0.2)
n_gaussians = 5
n_hidden = 20;
z_h = Dense(1, n_hidden, tanh)
z_π = Dense(n_hidden, n_gaussians)
z_σ = Dense(n_hidden, n_gaussians, exp)
z_μ = Dense(n_hidden, n_gaussians);
pi = Chain(z_h, z_π, softmax)
sigma = Chain(z_h, z_σ)
mu = Chain(z_h, z_μ);
#We need to implement this loss function ourselves:
function gaussian_distribution(y, μ, σ)
# periods are used for element-wise operations
result = 1 ./ ((sqrt(2π).*σ)).*exp.(-0.5((y .- μ)./σ).^2)
end;
function mdn_loss(π, σ, μ, y)
result = π.*gaussian_distribution(y, μ, σ)
result = sum(result, dims=1)
result = -log.(result)
return mean(result)
end;
pars = Flux.params(pi, sigma, mu)
opt = ADAM()
n_epochs = 8000;
#Finally we write the training loop.
# lowest-level?
data = [(y, x)]
#1 Defining l outside of do block and using gradient / Flux.gradient function
for epoch = 1:n_epochs
# forward
pi_out = pi(y)
sigma_out = sigma(y)
mu_out = mu(y)
# backward
l = 0f0 # define l before entering into do block to access later
gs = Flux.gradient(pars) do
l = mdn_loss(pi_out, sigma_out, mu_out, x)
end
Flux.update!(opt, pars, gs)
if epoch % 1000 == 0
println("Epoch: ", epoch, " loss: ", l) # we can access l here without any undefined error
end
end
x_test = range(-15, stop=15, length=n_samples)
pi_data = pi(transpose(collect(x_test)))
sigma_data = sigma(transpose(collect(x_test)))
mu_data = mu(transpose(collect(x_test)));
plot(collect(x_test), transpose(pi_data), lw=2)
plot(collect(x_test), transpose(sigma_data), lw=2)
plot(collect(x_test), transpose(mu_data), lw=2)
#We can also plot the mean μₖ(x) for each Gaussian together with the range μₖ(x) ± σₖ(x):
plot(collect(x_test), transpose(mu_data), lw=2, ribbon=transpose(sigma_data),
ylim=(-12,12), fillalpha=0.3)
scatter!(transpose(y), transpose(x), alpha=0.05)
function gumbel_sample(x)
z = rand(Gumbel(), size(x))
return argmax(log.(x) + z, dims=1)
end
k = gumbel_sample(pi_data);
sampled = rand(Normal(),1, 1000).*sigma_data[k] + mu_data[k];
scatter(transpose(y), transpose(x), alpha=0.2)
scatter!(collect(x_test), transpose(sampled), alpha=0.5)
and with it the loss function does not evolve.:
Epoch: 1000 loss: 8.61979609988576
Epoch: 2000 loss: 8.61979609988576
Epoch: 3000 loss: 8.61979609988576
Epoch: 4000 loss: 8.61979609988576
Epoch: 5000 loss: 8.61979609988576
Epoch: 6000 loss: 8.61979609988576
Epoch: 7000 loss: 8.61979609988576
Epoch: 8000 loss: 8.61979609988576