Hi,
I work on a project involving the resolution of numerous (10K) linear optimization problems.
JuMP is very expressive and convenient allowing to work with different backend solvers : many thanks to the JuMP devs for their great work !
In my specific case where the different LP problems are both small and numerically close to each other, I need to update a given model because the construction of a new one for each LP would both cost to much time and prevent me from using warm starts (which are essential to the overall performance).
It took me quite some time to discover that the vector version of
set_normalized_rhs exist and that I didn’t need ParametricOptInterface to accelerate my updates.
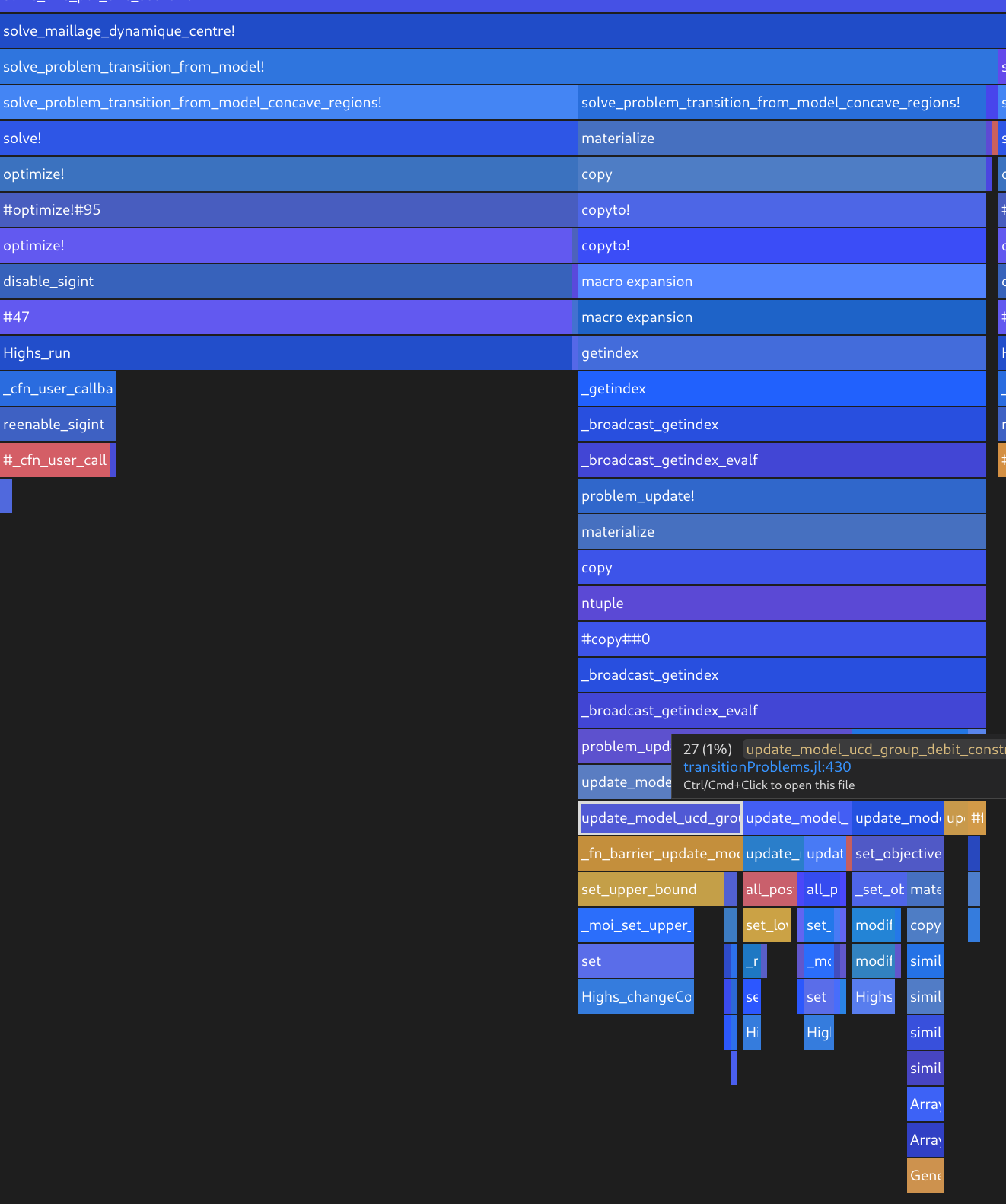
It also took me some time (I am relatively new to mathematical optimization) to realize that using lower/upper bounds of variables rather than additional constraints could accelerate significantly my computations.
Hence, I have been a bit disappointed by the absence of a vector method (a form that can be applied to a vector of variables) for set_lower_bound and set_upper_bound. I use broadcast but the time penalty is significant…
So my question is : why a vector form is available for constraint RHS modifications but not for modification of variables bound ?