Quick update – got it working with a single CUDA kernel! Here’s the code.
(click to expand)
module DynamicExpressionsCUDAExt
#! format: off
using CUDA
using DynamicExpressions: OperatorEnum, AbstractExpressionNode
using DynamicExpressions.EvaluateEquationModule: get_nbin, get_nuna
using DynamicExpressions.AsArrayModule: as_array
import DynamicExpressions.EvaluateEquationModule: eval_tree_array
function eval_tree_array(
tree::AbstractExpressionNode{T}, gcX::CuArray{T,2}, operators::OperatorEnum; _...
) where {T<:Number}
(outs, is_good) = eval_tree_array((tree,), gcX, operators)
return (only(outs), only(is_good))
end
function eval_tree_array(
trees::NTuple{M,N}, gcX::CuArray{T,2}, operators::OperatorEnum; _...
) where {T<:Number,N<:AbstractExpressionNode{T},M}
(; val, execution_order, roots, buffer) = as_array(Int32, trees...)
num_launches = maximum(execution_order)
num_elem = size(gcX, 2)
num_nodes = size(buffer, 2)
## Floating point arrays:
gworkspace = CuArray{T}(undef, num_elem, num_nodes)
gval = CuArray(val)
## Index arrays (much faster to have `@view` here)
gbuffer = CuArray(buffer)
gdegree = @view gbuffer[1, :]
gfeature = @view gbuffer[2, :]
gop = @view gbuffer[3, :]
gexecution_order = @view gbuffer[4, :]
gidx_self = @view gbuffer[5, :]
gidx_l = @view gbuffer[6, :]
gidx_r = @view gbuffer[7, :]
gconstant = @view gbuffer[8, :]
num_threads = 256
num_blocks = nextpow(2, ceil(Int, num_elem * num_nodes / num_threads))
_launch_gpu_kernel!(
num_threads, num_blocks, num_launches, gworkspace,
# Thread info:
num_elem, num_nodes, gexecution_order,
# Input data and tree
operators, gcX, gidx_self, gidx_l, gidx_r,
gdegree, gconstant, gval, gfeature, gop,
)
out = ntuple(
i -> @view(gworkspace[:, roots[i]]),
Val(M)
)
is_good = ntuple(
i -> true, # Up to user to find NaNs
Val(M)
)
return (out, is_good)
end
function _launch_gpu_kernel!(
num_threads, num_blocks, num_launches::Integer, buffer::AbstractArray{T,2},
# Thread info:
num_elem::Integer, num_nodes::Integer, execution_order::AbstractArray{I},
# Input data and tree
operators::OperatorEnum, cX::AbstractArray{T,2}, idx_self::AbstractArray, idx_l::AbstractArray, idx_r::AbstractArray,
degree::AbstractArray, constant::AbstractArray, val::AbstractArray{T,1}, feature::AbstractArray, op::AbstractArray,
) where {I,T}
nuna = get_nuna(typeof(operators))
nbin = get_nbin(typeof(operators))
(nuna > 10 || nbin > 10) && error("Too many operators. Kernels are only compiled up to 10.")
gpu_kernel! = create_gpu_kernel(operators, Val(nuna), Val(nbin))
for launch in one(I):I(num_launches)
@cuda threads=num_threads blocks=num_blocks gpu_kernel!(
buffer,
launch, num_elem, num_nodes, execution_order,
cX, idx_self, idx_l, idx_r,
degree, constant, val, feature, op
)
end
return nothing
end
# Need to pre-compute the GPU kernels with an `@eval` for each number of operators
# 1. We need to use an `@nif` over operators, as GPU kernels
# can't index into arrays of operators.
# 2. `@nif` is evaluated at parse time and needs to know the number of
# ifs to generate at that time, so we can't simply use specialization.
# 3. We can't use `@generated` because we can't create closures in those.
for nuna in 0:10, nbin in 0:10
@eval function create_gpu_kernel(operators::OperatorEnum, ::Val{$nuna}, ::Val{$nbin})
function (
# Storage:
buffer,
# Thread info:
launch::Integer, num_elem::Integer, num_nodes::Integer, execution_order::AbstractArray,
# Input data and tree
cX::AbstractArray, idx_self::AbstractArray, idx_l::AbstractArray, idx_r::AbstractArray,
degree::AbstractArray, constant::AbstractArray, val::AbstractArray, feature::AbstractArray, op::AbstractArray,
)
i = (blockIdx().x - 1) * blockDim().x + threadIdx().x
if i > num_elem * num_nodes
return nothing
end
node = (i - 1) % num_nodes + 1
elem = (i - node) ÷ num_nodes + 1
if execution_order[node] != launch
return nothing
end
cur_degree = degree[node]
cur_idx = idx_self[node]
if cur_degree == 0
if constant[node] == 1
cur_val = val[node]
buffer[elem, cur_idx] = cur_val
else
cur_feature = feature[node]
buffer[elem, cur_idx] = cX[cur_feature, elem]
end
else
if cur_degree == 1
cur_op = op[node]
l_idx = idx_l[node]
Base.Cartesian.@nif(
$nuna,
i -> i == cur_op,
i -> let op = operators.unaops[i]
buffer[elem, cur_idx] = op(buffer[elem, l_idx])
end
)
else
cur_op = op[node]
l_idx = idx_l[node]
r_idx = idx_r[node]
Base.Cartesian.@nif(
$nbin,
i -> i == cur_op,
i -> let op = operators.binops[i]
buffer[elem, cur_idx] = op(buffer[elem, l_idx], buffer[elem, r_idx])
end
)
end
end
return nothing
end
end
end
#! format: on
end
The key function is _launch_gpu_kernel which actually launches the kernels. Basically, each launch, it goes one up the tree to the next node that can be computed, and spawns all the threads to all (array elements) x (available nodes).
In gif form, the CUDA launches are like this:
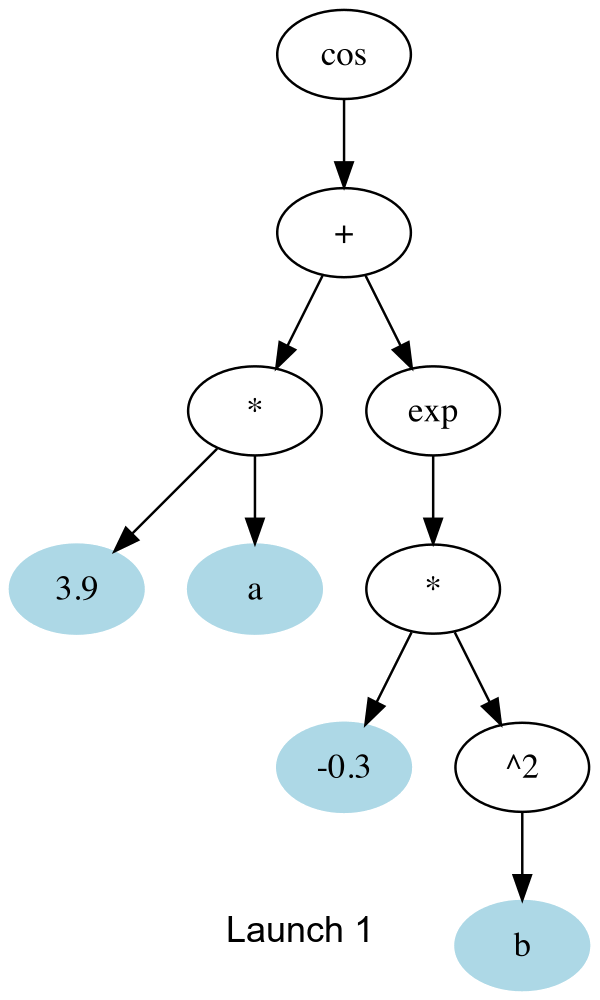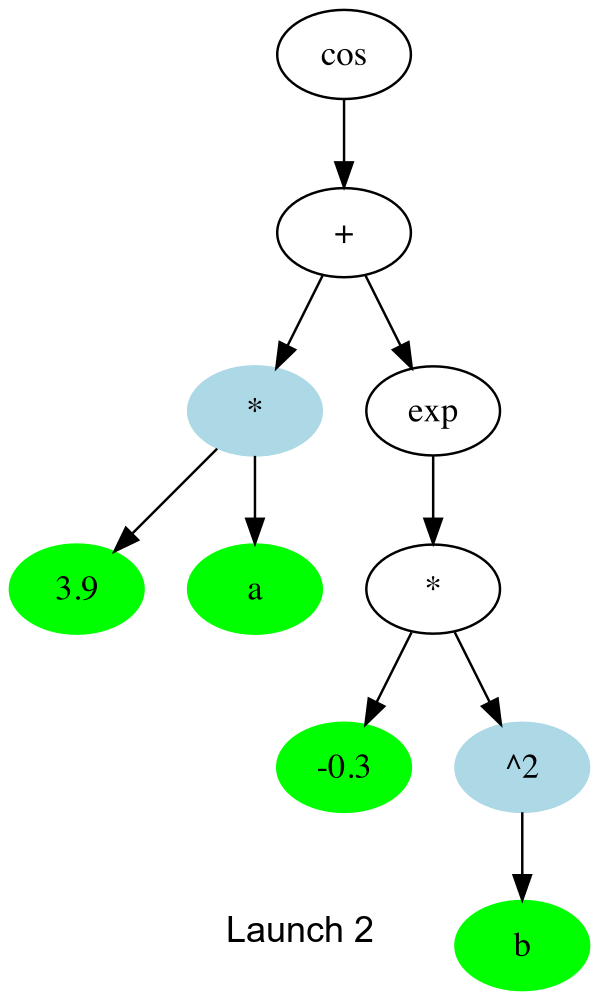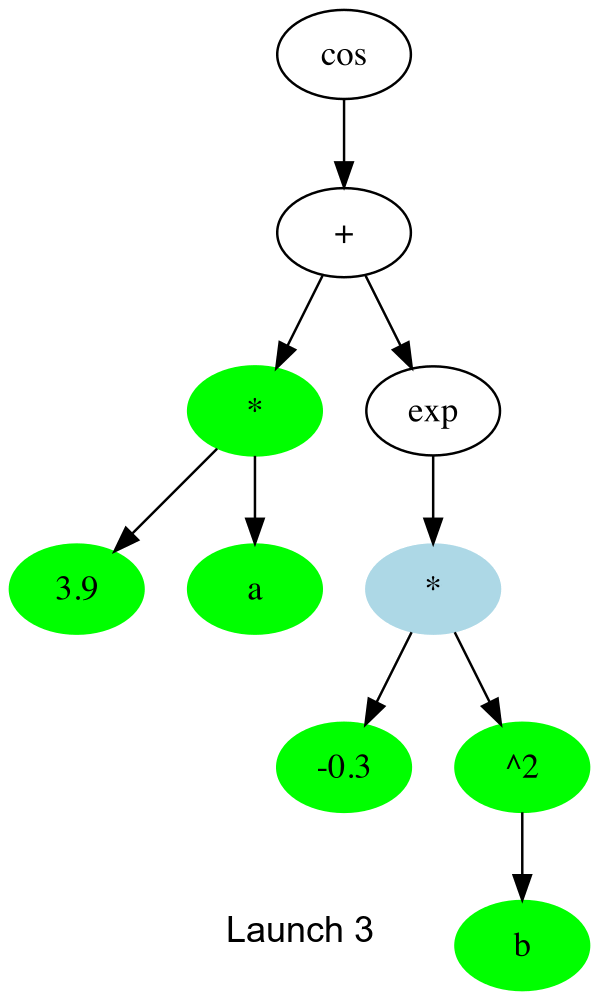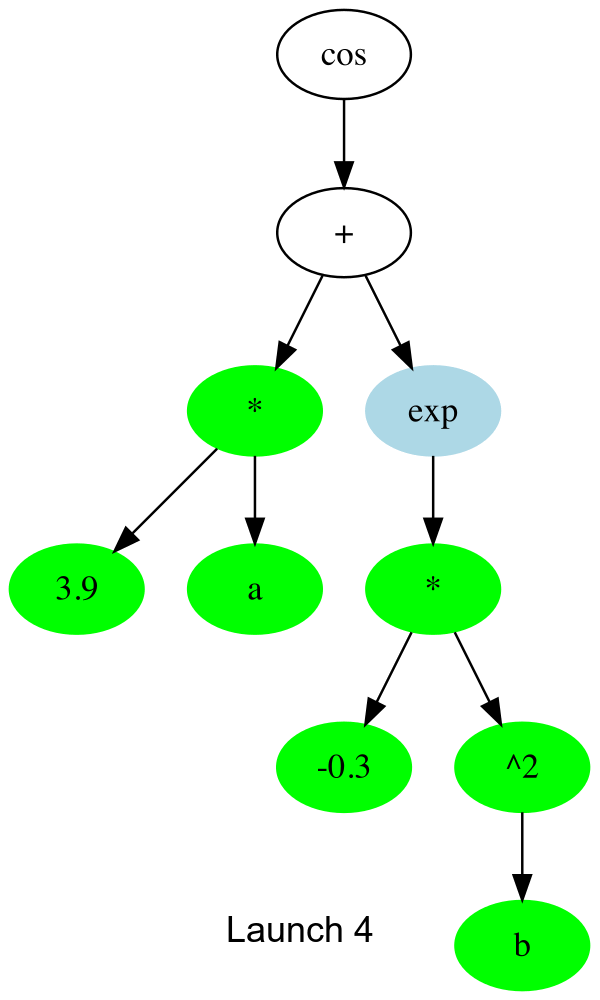
And the threads which don’t compute anything simply quit early. This is about 30% faster than the initial naive version I tried. I’m assuming there’s remaining slowness due to me misusing some part of CUDA.jl, so any other tips much appreciated ![]()
Also I want to note that this new attempt allows batching over expressions! So you can do, e.g.,
julia> eval_tree_array((tree1, tree2, tree3), X, operators)
and it will put them in one big array and work on them at the same time. So maybe this is a way to get your suggestion working @Raf – I need to find a way to batch evaluate over expressions.
Finally, here’s the profiling results:
julia> CUDA.@profile eval_tree_array(tree, X, operators)[1]
Profiler ran for 638.25 µs, capturing 376 events.
Host-side activity: calling CUDA APIs took 377.89 µs (59.21% of the trace)
┌──────────┬────────────┬───────┬───────────────────────────────────────┬─────────────────────────┐
│ Time (%) │ Total time │ Calls │ Time distribution │ Name │
├──────────┼────────────┼───────┼───────────────────────────────────────┼─────────────────────────┤
│ 21.93% │ 139.95 µs │ 27 │ 5.18 µs ± 15.46 ( 1.43 ‥ 82.49) │ cuMemAllocFromPoolAsync │
│ 19.24% │ 122.79 µs │ 31 │ 3.96 µs ± 3.28 ( 2.62 ‥ 20.98) │ cuLaunchKernel │
│ 5.53% │ 35.29 µs │ 9 │ 3.92 µs ± 4.71 ( 2.15 ‥ 16.45) │ cuMemcpyHtoDAsync │
│ 2.69% │ 17.17 µs │ 1 │ │ cuMemcpyDtoHAsync │
│ 1.57% │ 10.01 µs │ 11 │ 910.33 ns ± 381.74 (476.84 ‥ 1668.93) │ cuStreamSynchronize │
└──────────┴────────────┴───────┴───────────────────────────────────────┴─────────────────────────┘
Device-side activity: GPU was busy for 188.59 µs (29.55% of the trace)
┌──────────┬────────────┬───────┬─────────────────────────────────────┬──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
│ Time (%) │ Total time │ Calls │ Time distribution │ Name ⋯
├──────────┼────────────┼───────┼─────────────────────────────────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
│ 21.52% │ 137.33 µs │ 14 │ 9.81 µs ± 1.72 ( 6.91 ‥ 12.87) │ _Z3_5913CuDeviceArrayI7Float32Li2ELi1EE5Int64S1_S_I4BoolLi1ELi1EES_IS0_Li2ELi1EES_I5Int32Li1ELi1EES_IS3_Li1ELi1EES_IS3_Li1ELi1EES_I5UInt8Li1ELi1EES_IS2_Li1ELi1EES_IS0_Li1ELi1EES_I6UInt16L ⋯
│ 4.41% │ 28.13 µs │ 14 │ 2.01 µs ± 0.12 ( 1.91 ‥ 2.15) │ _Z16broadcast_kernel15CuKernelContext13CuDeviceArrayI4BoolLi1ELi1EE11BroadcastedI12CuArrayStyleILi1EE5TupleI5OneToI5Int64EE2__S4_I8ExtrudedIS0_I5Int32Li1ELi1EES4_IS1_ES4_IS6_EES9_EES6_ ⋯
│ 1.91% │ 12.16 µs │ 9 │ 1.35 µs ± 0.12 ( 1.19 ‥ 1.43) │ [copy pageable to device memory] ⋯
│ 0.67% │ 4.29 µs │ 1 │ │ _Z22partial_mapreduce_grid8identity7add_sum7Float3216CartesianIndicesILi1E5TupleI5OneToI5Int64EEES2_ILi1ES3_IS4_IS5_EEE3ValILitrueEE13CuDeviceArrayIS1_Li2ELi1EE11BroadcastedI12CuArrayStyl ⋯
│ 0.41% │ 2.62 µs │ 1 │ │ _Z16broadcast_kernel15CuKernelContext13CuDeviceArrayI7Float32Li1ELi1EE11BroadcastedI12CuArrayStyleILi1EE5TupleI5OneToI5Int64EE1_S4_I8ExtrudedIS0_IS1_Li1ELi1EES4_I4BoolES4_IS6_EES1_EES6_ ⋯
│ 0.37% │ 2.38 µs │ 1 │ │ _Z15getindex_kernel15CuKernelContext13CuDeviceArrayI7Float32Li1ELi1EES0_IS1_Li2ELi1EE5TupleI5Int64S3_E5SliceI5OneToIS3_EES3_ ⋯
│ 0.26% │ 1.67 µs │ 1 │ │ [copy device to pageable memory] ⋯
└──────────┴────────────┴───────┴─────────────────────────────────────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
1 column omitted
Edit: Improved some of the redundant allocations. Now I’m seeing the GPU have a 3x improvement in perf on even 1,000 element arrays.