I have been trying to improve Julia’s DataFrame group-by for a while now and I think I am able to synthesized my thinking into APIs.
Here are my synthesized recommendation (as of 25th Feb 2018)
Recommendation
Why?
Benchmark Status
If you need to perform group-by A LOT use JuliaDB.jl/IndexedTables.jl
You can create indexes on the group-by columns and it is generally faster than other available methods
No benchmarks; as the benchmarks was intended to test non-indexing performance
If the # of unique groups is small use DataFramesMeta.jl’s @by
DataFramesMeta.jl uses a hashtable (Dict) in the background and it works pretty well for types with a small number of unique values (due to efficient CPU cache usage I assume)
Benchmarked. it beats FastGroupBy.jl in one case
FastGroupBy.jl’s fast algorithm will eventually but contributed back into DataFrames.jl and JuliaDB.jl. Use DataFramesMeta.jl instead and the group-by will gain a speed boost when these algorithms get there in a PR
FastGroupBy.jl tends to have the fastest group-by algorithms. Use CategoricalArrays.jl whenever possible as the group-by vectors. FastGroupBy.jl implemented an optimization that is not yet in data.table
Benchmarked
if nice API is more important than speed then use DataFramesMeta.jl
It’s got the cleanest API and easy to remember verbs
Benchmarked
Do NOT use Query.jl if performance matters
You can see in my benchmarking code that I have benchmarked Query.jl but it’s way too slow for even 10m records. This issue has been reported before, I am not sure the design of Query.jl can support performance-oriented group-bys
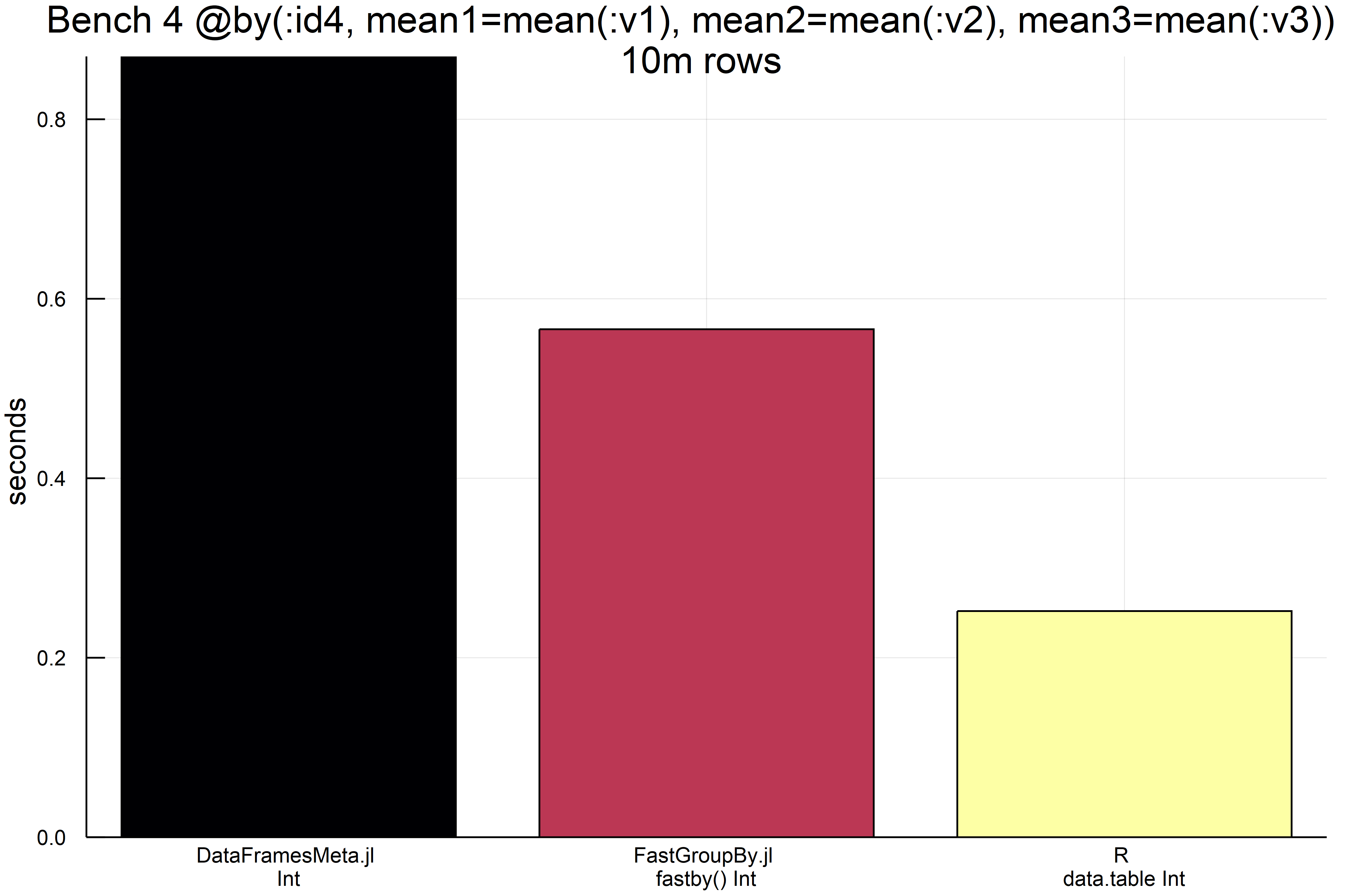
Benchmarked; not plotted
Benchmarks
Group-by in Julia using strings as the group-by variable tends to result in much slower timings than R’s data.table. This can’t be avoided as R has string interning. So I have provided benchmarks for when the group-by is a string (data.table is faster) vs when the group-by is a categorical (FastGroupBy.jl 10x faster) for one particular case to illustrate. When the group-by is a reduce operation e.g. sum but not mean, then using fgroupreduce will yield faster results. Again do not try to use FastGroupBy.jl just yet, as it’s immature and only have algorithms for the five types of group-by’s benchmarked below. Also R’s data.table is faster than any Julia implementation unless the group-by variables is a cateogrical; but FastGroupBy.jl beats the best known Julia solutions (without indexing) by a wide margin most of the time, so its algorithms which are radix-sort based should be contributed back to DataFrames.jl and JuliaDB.jl
DataFramesMeta uses the plain DataFrames by method, right? Then its slowness is due in large part to the type instability of the reduction, since the type of the columns isn’t encoded in the object type. I’m afraid the performance of the algorithm won’t be the main determinant as long as we haven’t fixed that. See this issue.
I think you can address the above by updating the DataFramesMeta.jl’s macro @by to make it do a “translation” step. The trick is not to work with DataFrames but have macros that “break it down” so that the functions work on vectors or tuples of vectors; so NamedTuples would be one implementation.
You can write the functions so that they are called by passing columns into them. We have macros like DataFramesMeta that works like this
@> df begin
@by(:bygroup, sum(:v1)
end
you see how that can be transformed into something like groupreduce(+, df[:bygroup], df[:v1]) and if you make that a “function boundary” then optimized type-stable code will be called at that point. You can see some of it in action in my benchmarking code.
I can probably post an example of this in FastGroupBy.jl next weekend.
I have an idea about how to design the API and have the implementation use some weighted graphs and apply Dykstra’s algorithm to find optimal ways to perform these types of operation. There is a good chance I will blog about it in the next 6 months or so.
Yes, that approach would work. Though I’m not sure it’s easy to implement in full generality, e.g. if the function returns a data frame for each group (which by currently supports). Sometimes it’s also useful to have access to all columns in the data frame, e.g. if you want to standardize them within each group. So it would be useful to also make by more efficient with plain DataFrames.
Yeah. I think some functions will have to work with Dataframe but again all functions should woke with vectors and have function boundaries so everything is optimised whenever possible. In R’s data.table they basically recognise that you what mean(v1) and provide a fast path for that.
Anyway, that how DataFramesMeta should work as well.
Functions that deal with DataFramesMeta e.g size should work fine. But the moment you work with as vector it should be called via a function so the function boundary effect can take place
Might update this at some point. Currently I only spend Sunday mornings on OSS’s work, so progress will be slow. But I think DataFrames with DataFramesMeta is the way to go. Other table libraries have lost steam