Hi, sorry for the delayed response.
Yes, that’s right. Appreciate the suggestion, and I spent some time exploring it. I did some tests on the run-time and memory performance using the “Array” method, which applies the CNN to one large array of images, and the “VecArray” method, which broadcasts the CNN over a vector of arrays of images. I was interested to see how performance changes with
- the size of the CNN, in terms of the number of trainable parameters,
- m, the number of “locations”; that is, the number of elements in the vector that we are broadcasting over, and
- n_i, the number of images at each location; that is, the number of images stored in each element of the vector.
I looked at two CNNs, one with ~100 parameters, and another with ~420,000 parameters. The large CNN is reflective of the size of network I am using in my application. I used all combinations of m \in \{16, 32, 64, 128\} and n _i \in \{1, 10, 25, 50, 75, 100\}. (These values of m are reflective of typical mini-batch sizes.)
Run-times: Using the small CNN yields a large discrepancy between run-times, while there is little difference when using the large CNN:
Small CNN (~100 parameters):
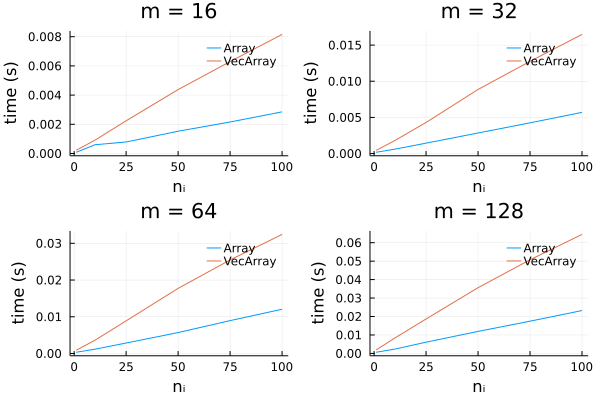
Large CNN (~420,000 parameters):

Memory usage: there appears to be a constant penalty to using the Vector{Array} approach, which is fixed for a given value of m (i.e., it does not change with n_i):
Small CNN (~100 parameters):

Large CNN (~420,000 parameters):

Note that this was done on the CPU: The results may change on the GPU. The results suggest that, for the large CNN, there isn’t a massive difference in terms of run time and memory usage when n_i is “large enough” (e.g., for n_i = 50).
I should note that I made a mistake by looking at the case of m = 1000 and n_i = 1 in my original question. In this configuration, applying a CNN to an array and then aggregating is indeed much better than broadcasting over a vector of arrays, but this is not practically relevant for my application.
Thanks again for your helpful comments!