[not sure this is the best category, mods feel free to move]
Hi all,
I wanted to share our recent conference proceeding on using Julia in a real time application: [2407.07207] Real-time adaptive optics control with a high level programming language
Our use case requires processing 2-3 high speed camera streams (up to ~1 thousand frames per second) and responding with hardware commands.
The application is an adaptive optics system in the SPIDERS instrument that will sit behind the Subaru telescope in Hawaii and dynamically compensate for the turbulence of the Earth’s atmosphere, revealing fainter exoplanets.
Besides the usual performance recommendations (make sure everything is type stable, avoid allocations, etc), we wanted to share the architecture we settled on after a few iterations.
We built the software as a pipeline composed of independent single-threaded Julia processes. This was to mitigate the stop-the-world GC behaviour and allow us to decouple soft real time processes, where we want to be able to allocate freely, and hard real time processes which should never pause.
Thankfully with this design, the heap size of each process remains small. If we do trigger an allocation and GC pause the resulting GC latency is typically sub 0.5ms. This is nice to fall back on for e.g. error paths or cleanup paths where we we don’t want to spend the same amount of time optimizing the code as we do for the hot path.
Within each component, we structure the code using a hierarchical state machine. We write callbacks that respond to events in a given operation state and either perform some action, or transition to another state. This worked well because it encourages devs to write small functions, avoid closures (and the closure capturing performance bug), and specify the types of all variables in the state machine definition.
The communication between processes was accomplished with Aeron.jl. Aeron is a latency optimized IPC and UDP communication library coming from the high frequency trading sector.
Within each aeron message, we used an implementation of SimpleBinaryEncoding. This provides a stuct and/or array like interface to a flat contiguous UInt8 buffer without any memory copying for encode/decode. It does require you to specify each message type using an XML schema however.
We also ran everything on a linux kernel with the RT PREMPT patch and used thread pinning, although these steps shouldn’t really be necessary with Aeron.
Aeron has its own message archiving and replay functionality but we ended up building our own built over SQLite.jl.
To interact with all the distributed components of the system, we built a Julia library, a command line interface, and a graphical user interface using CImGui.jl (great package @Gnimuc !)
In the end, without yet having spent too much time on configuring our hardware and OS, we get pretty decent latency numbers:

Screen shot of the GUI, which runs at 60Hz!:
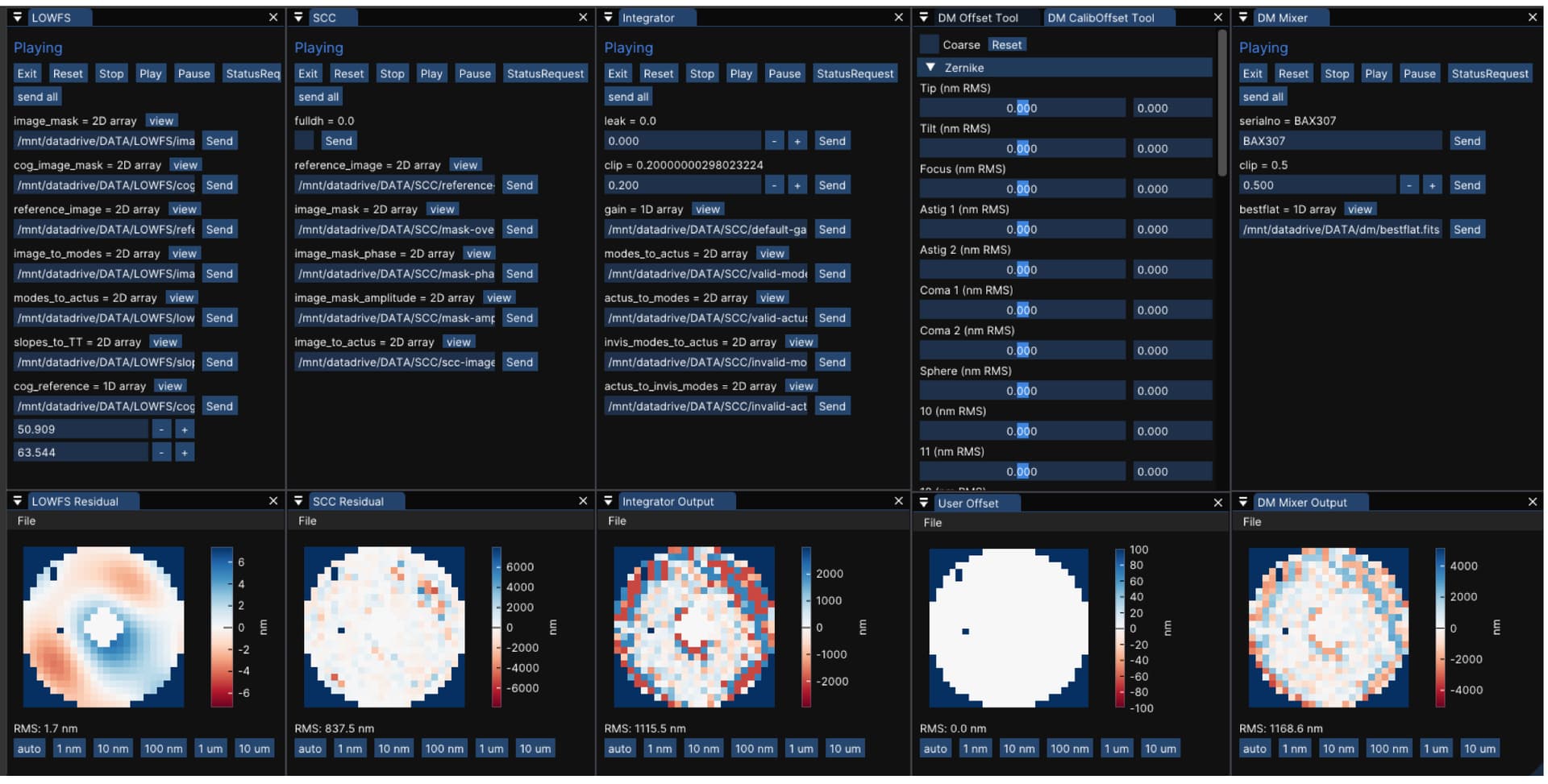
We hope this provides others with some confidence that Julia is also a great fit for their real time applications!
Wish list
A few wish-list items based on this experience:
- Escape analysis and stack allocation of temporary arrays. This would make it a lot easier for less experienced devs to write non-allocating real time loops and not trigger the GC.
- Relatedly, some of the work towards integrating other GC backends might be interested if there’s one that could guarantee shorter pauses.
- The recent PR implementing a first-party
TypedCallableis promising. Currently we use FunctionWrappers.jl to implement our state machines, but that library triggers a false alarm warning about a memory allocation from AllocCheck.jl.
Happy to answer any questions, and interested to hear from anyone else using Julia in this domain.
Thanks!
