I’m excited to announce LoopVectorization.
LoopVectorization provides the @avx macro.
This macro can be prepended to a for loop or a broadcast statement, and it tries its best to vectorize the loop.
It can handle nested loops. It models the cost of evaluating the loop, and then unrolls either one or two loops.
Examples
Lets jump straight into the deep end with the classic: matmul.
@inline function gemmavx!(C, A, B)
@avx for i ∈ 1:size(A,1), j ∈ 1:size(B,2)
Cᵢⱼ = 0.0
for k ∈ 1:size(A,2)
Cᵢⱼ += A[i,k] * B[k,j]
end
C[i,j] = Cᵢⱼ
end
end
For comparison, we have:
- Intel MKL, single threaded.
- Julia (
@inboundsand@simd) - Clang + Polly
- GFortran
- GFortran, matmul intrinsic
- icc
- ifort
- ifort, matmul intrinsic
You can see the Julia code I used to run the benchmarks here. The C and Fortran code are in the “looptest.c” and “looptest.f90” files of the same directory. The “driver.jl” file contains the script I ran to run the benchmarks (note, as is, it will run benchmarks in parallel; take care that this doesn’t cause problems).
loadsharedlibs.jl contains the commands (and flags) I used to compile the C and Fortran code.
I’ll add the new Flang once it is released. It is an LLVM Fortran compiler that uses MLIR, making it promising.
I benchmarked A * B, A' * B, and A * B'.
To represent LoopVectorization.jl, I used the gemmavx! function above for all three.
Each of the others, however, required a new function for each version.
A * B
I used the following Julia function (and the same order for C and Fortran):
function jgemm!(C, A, B)
C .= 0
M, N = size(C); K = size(B,1)
@inbounds for n ∈ 1:N, k ∈ 1:K
@simd ivdep for m ∈ 1:M
C[m,n] += A[m,k] * B[k,n]
end
end
end

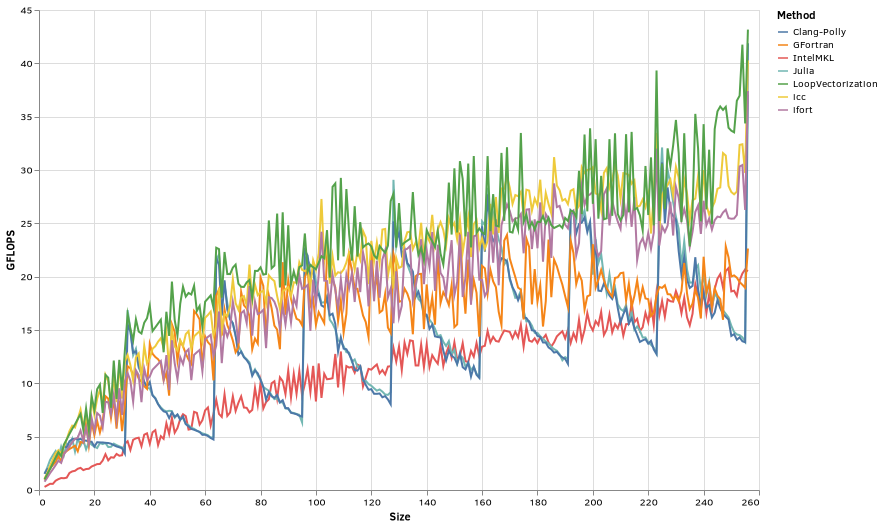
The plots cover all square matrices of sizes 2x2 through 256x256.
MKL is of course the fastest. Its performance drops once it starts running out of L2 cache.
LoopVectorization does second best. Its performance peaks between 40x40 and 64x64 matrices, but the performance is fairly steady over the size range after that.
Of the others, gfortran’s matmul intrinsic performs best as a function of matrix size, steadily increasing in performance, starting to take 3rd place at around 140x140.
Both Intel-Fortran versions were just on it’s heals over that range, and well ahead for matrices smaller than 140x140.
Throughout these benchmarks, Clang-Polly and Julia’s performance are highly variable, a “signature” of LLVM’s loop optimizer. But it did better than icc, gfortran-loops, and Julia.
A’ * B
Now we have A' * B:
@inline function jgemm!(C, Aᵀ::Adjoint, B)
A = parent(Aᵀ)
@inbounds for n ∈ 1:size(C,2), m ∈ 1:size(C,1)
Cₘₙ = zero(eltype(C))
@simd ivdep for k ∈ 1:size(A,1)
Cₘₙ += A[k,m] * B[k,n]
end
C[m,n] = Cₘₙ
end
end
Note that every function receiving transposed (adjoint) matrices was made @inline to avoid the allocation of tranposing the array. Perhaps I will just preallocate the tranpose the next time I update the benchmarks.
Here, we are essentially taking M * N dot products (where C is an M by N matrix), as we iterate over the M columns of A and N columns of B. As discussed later alongside the dot product benchmarks, the limiting factor is the rate at which the CPU can perform loads. Blocking – that is, loading from 4 columns of A and 4 columns of B to perform 4*4=16 products – helps us achieve much higher GFLOPS here than with the single dot products.

I don’t know what MKL is doing here, but it attains nearly the same performance as when A is not tranposed, which is not something I’ve been able to manage. Perhaps it somehow packs very efficiently to transpose A?
LoopVectorization and the three Intel-compiled functions are all probably doing the same thing: evaluating the loop order as written for the naive version, but blocked somehow to get a lot more arithmetic done per load.
GFortran (loops or built in), Clang-Polly, and Julia do not, and are therefore slow.
A * B’
This one is a lot like A * B, in that the most efficient algorithm involves loading contiguous elements from A and broadcasting scalars from B. B is just traversed in a different order.

Yet that change was enough to throw off implementations that get by more based on pattern matching vs an actual vectorization model, namely gfortran’s matmul intrinsic – you’d naturally expect a matmul function to be specially optimized, and it’s merely unfortunate that they don’t seem to have fast versions for the transpose – or Polly, which tries to detect matmul and emit fast code.
MKL is obviously fastest. LoopVectorization is next, followed by all three intel-compiled versions.
Dot Products
To get into a little about how it works, lets start with a simple example, a dot product:
function jdot(a, b)
s = 0.0
@inbounds @simd ivdep for i ∈ eachindex(a, b)
s += a[i] * b[i]
end
s
end
function jdotavx(a, b)
s = 0.0
@avx for i ∈ eachindex(a, b)
s += a[i] * b[i]
end
s
end
Most recent CPUs are capable of 2x aligned loads, and 2x fma per clock cycle.
Because the dot product requires 2 loads per fma, that bottle necks us at 1 fma per clock cycle.
However, it takes 4 clock cycles to complete an fma instruction on many recent CPUs. And to complete one iteration of s_new = s_old a[i] * b[i], we need to have calculated s_old.
For this reason, LoopVectorization unrolls the loop by a factor of 4, so that we have four copies of s, and a new fma instruction can be started on every clock cycle.
The worst performer here is Julia’s builtin dot (which I believe uses BLAS), which isn’t too surprisng here.
Next worst are the two LLVM-loop-optimized versions, suffering from highly variable performance based on the length of the loop remainders. At their peak, they match the competition, but Julia and Clang-Polly quickly fall off to the bottom from there.
gfortran isn’t doing too well either. I’d have to look more into what is going on there.
Now, consider the selfdot:
function jselfdot(a)
s = 0.0
@inbounds @simd ivdep for i ∈ eachindex(a)
s += a[i] * a[i]
end
s
end
function jselfdotavx(a)
s = 0.0
@avx for i ∈ eachindex(a)
s += a[i] * a[i]
end
s
end
Here we only need a single load per fma, meaning that it could potentially perform 2 fmas per clock cycle, requiring 8 concurrent instances.
But LLVM still unrolls it by a factor of 4.

However, that doesn’t seem to limit its peak performance. Perhaps because none of the functions are achieving half the GFLOPS of matrix multiplication: the fma units are spending at least half their time idle.
The pattern is similar to what we saw for the single argument dot product.
Three-argument, generalized, dot product
This computes x * A * y.
function jdot3(x, A, y)
M, N = size(A)
s = zero(promote_type(eltype(x), eltype(A), eltype(y)))
@inbounds for n ∈ 1:N
@simd ivdep for m ∈ 1:M
s += x[m] * A[m,n] * y[n]
end
end
s
end
function jdot3avx(x, A, y)
M, N = size(A)
s = zero(promote_type(eltype(x), eltype(A), eltype(y)))
@avx for m ∈ 1:M, n ∈ 1:N
s += x[m] * A[m,n] * y[n]
end
s
end
Like in A' * B, we can improve performance a lot by blocking. A single load from x can be multiplied with several loads of y, and vice versa. Recognizing this is a boon for performance:

When operating on matrices (and forced to do vector loads instead of broadcasts), LoopVectorization does best when the number of rows in the matrix is a multiple of 8. This is because when this happens, each of its columns will be 64 byte alligned, and the CPU can load 2 vectors per clock cycle. Othererwise, it can only load once per clock cycle from each column whose start isn’t at a memory address divisble by 64.
The effect is particularly striking here, because we do not get any reuse out of a load from A; we need 1 load from A per [multiplication & fma], meaning it must constantly be loading.
LoopVectorization does best here, while icc and ifort are close behind.
MKL here meant using the 3-argument dot(x, A, y), new to Julia 1.4.
I haven’t looked into how it’s implemented, but am guessing it is pure Julia based on how the performance behaves as a function of input size: like the other two LLVM versions.
Matrix * vector
‘gemv’ benchmarks, A * x:
function jgemv!(y, A, x)
y .= 0.0
@inbounds for j ∈ eachindex(x)
@simd ivdep for i ∈ eachindex(y)
y[i] += A[i,j] * x[j]
end
end
end
@inline function jgemvavx!(y, A, x)
@avx for i ∈ eachindex(y)
yᵢ = 0.0
for j ∈ eachindex(x)
yᵢ += A[i,j] * x[j]
end
y[i] = yᵢ
end
end

I went into detail into matrix-vector multiplication here.
I think LoopVectorization did best over this range, but by the end MKL and gfortran began to overtake it.
LoopVectorization does not model memory yet. Ideally it would perform some blocking pattern that has better memory access patterns, but this is what we get for now,
We also consider A' * x, which is equivalent to x' * A (row-vector * matrix multiplciation):
@inline function jgemv!(y, Aᵀ::Adjoint, x)
A = parent(Aᵀ)
@inbounds for i ∈ eachindex(y)
yᵢ = 0.0
@simd ivdep for j ∈ eachindex(x)
yᵢ += A[j,i] * x[j]
end
y[i] = yᵢ
end
end
Like with matrix multiplication, I could reuse the @avx function without modification for the transpose. Benchmarks:

LoopVectorization and the Intel compilers are close, with LoopVectorization leading on multiples of 8. GFortran (both the matmul intrinsic and loopy version), and then Clang-Polly and Julia follow, exhibiting the trademark performance degradation over intervals of 4*vector width.
Sum of Squared Error
Here, we consider the sum of squared error: sum(abs2, y .- X * β) (alternatively, it is proportional to the negative log likelihood of a ordinary least squares model).
function jOLSlp(y, X, β)
lp = 0.0
@inbounds @fastmath for i ∈ eachindex(y)
δ = y[i]
@simd for j ∈ eachindex(β)
δ -= X[i,j] * β[j]
end
lp += δ * δ
end
lp
end
function jOLSlp_avx(y, X, β)
lp = 0.0
@avx for i ∈ eachindex(y)
δ = y[i]
for j ∈ eachindex(β)
δ -= X[i,j] * β[j]
end
lp += δ * δ
end
lp
end

The MKL code was:
function sse!(Xβ, y, X, β)
mul!(copyto!(Xβ, y), X, β, 1.0, -1.0)
dot(Xβ, Xβ)
end
LoopVectorization was able to optimize that loop nest well. None of the other compilers could.
The Intel compilers and GFortran each have a faster vectorized exp implementation than SLEEFPirates.
I did not use square matrices here. If s is the size in the above chart, y and β were vectors of lengths 3s ÷ 2 and s ÷ 2, respectively.
Broadcasting
Lets start with something simple:
b = @avx exp.(a)
@avx @. b = log(a)
exp benchmarks:

Base Julia cannot vectorize elemental functions like exp, so the advantage here is substantial.
It can also handle multidimensional broadcasts:
a = rand(M); B = rand(M, N); c = rand(N);
D = @avx @. a + B * c'
@avx @. D = a + B * c'
Currently, arrays are not allowed to have dimensions of size 1. Either I’ll allow users to work around this via providing information on which dimensions are of size 1, or by replacing all strides associated with these dimensions as 0.

A + A’
A matrix plus its own transpose – not too complicated.

Note that LoopVectorization will always use vector gathers from A' here, which will probably be slower on computers without AVX512 than the regular Julia implementation.
But on the computer I benchmarked on, this implementation does much better than both the default Julia, and Clang-Polly.
Random accesses
This is @cortner’s code:
function randomaccess(P, basis, coeffs::Vector{T}) where {T}
C = length(coeffs)
A = size(P, 1)
p = zero(T)
@fastmath @inbounds for c ∈ 1:C
pc = coeffs[c]
for a = 1:A
pc *= P[a, basis[a, c]]
end
p += pc
end
return p
end
function randomaccessavx(P, basis, coeffs::Vector{T}) where {T}
C = length(coeffs)
A = size(P, 1)
p = zero(T)
@avx for c ∈ 1:C
pc = coeffs[c]
for a = 1:A
pc *= P[a, basis[a, c]]
end
p += pc
end
return p
end

LoopVectorization, icc, and gfortran did best here.
I checked gfortran and the regular Julia’s assembly output to confirm that both of them (like LoopVectorization) used gather instructions to vectorize the loop.
LLVM was more aggressive about it than LoopVectorization or gfortran, probably explaining why the latter two were faster and much less sensitive to the size of the arrays.
Current Limitations
- It only handles rectangular iteration spaces.
- Always uses cartesian indexing for broadcasts. If the broadcast includes multidimensional arrays that are all of the same size, it may be worthwhile
vecing them first. - Does not model memory movement or locality in making optimization decisions. I plan to do this eventually. The intention would be for it to consider creating a macro and micro kernel. The micro-kernel handles register-level optimizations, and the macro kernel handles cache-friendliness following this work.
- Aliasing between distinct arrays is forbidden. You can’t
@avxacumsum. - It doesn’t do loop “splitting”. Sometimes it would be better to break a loop up into 2 or more loops.
- It cannot handle multiple loops at the same level within the loop nest.
I’m also not married to the @avx name, given that the name is only relevant for recent x86 CPUs. The name @vectorize is currently reserved, because there it already defines an older (and much simpler) macro. I may eventually deprecate it, but I have about a dozen unregistered packages still depending on it for the time being.
Before using @avx, I’d always recommend testing it for both correctness and performance.
I’d like both improving modeling, as well as new strategies for lowering loops. Better/more performance, documentation, tests, etc are all always wanted. PRs and issues are welcome.