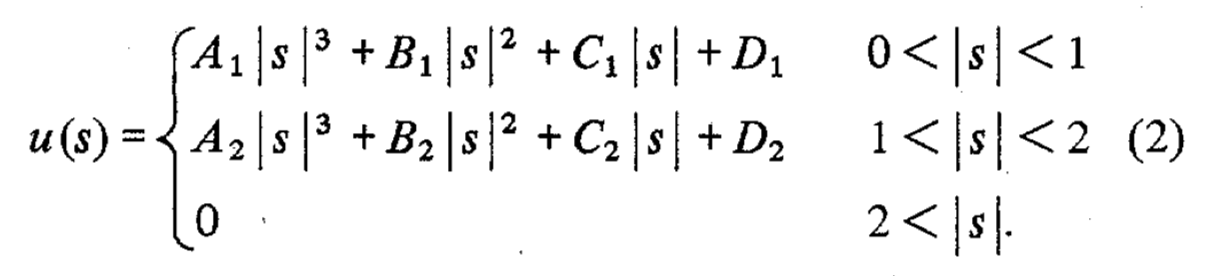Hi Julia people ![]()
I made this registered package for interpolation: GitHub - NikoBiele/ConvolutionInterpolations.jl: A Julia package for smooth high-accuracy N-dimensional interpolation using separable convolution kernels
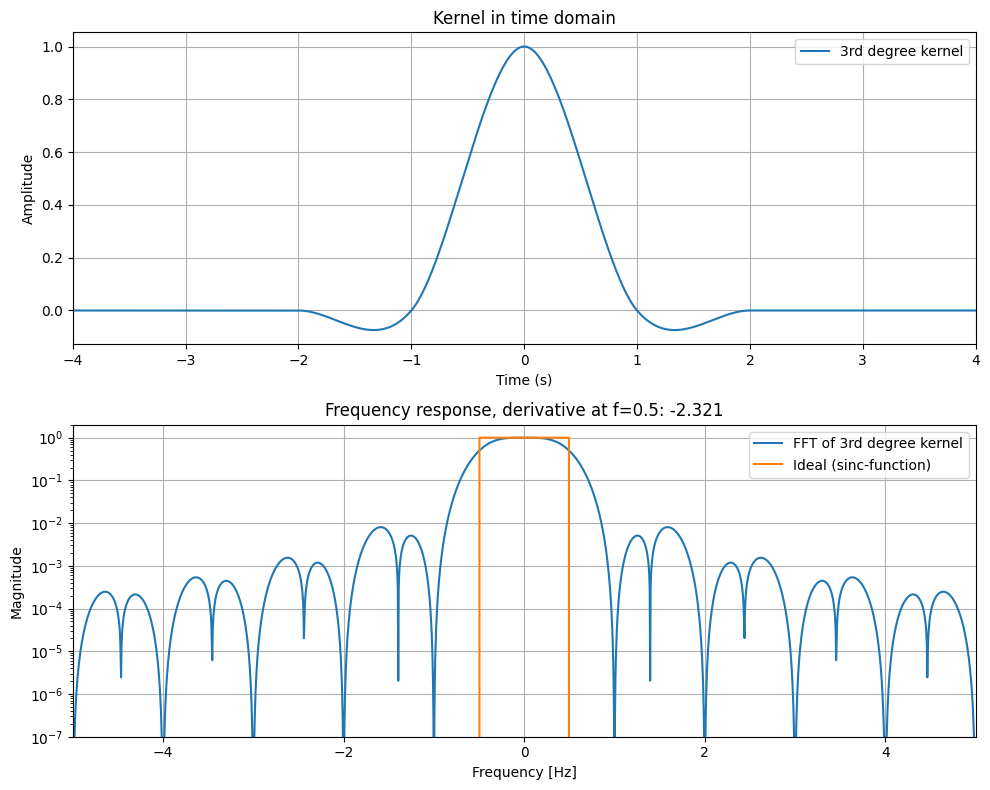
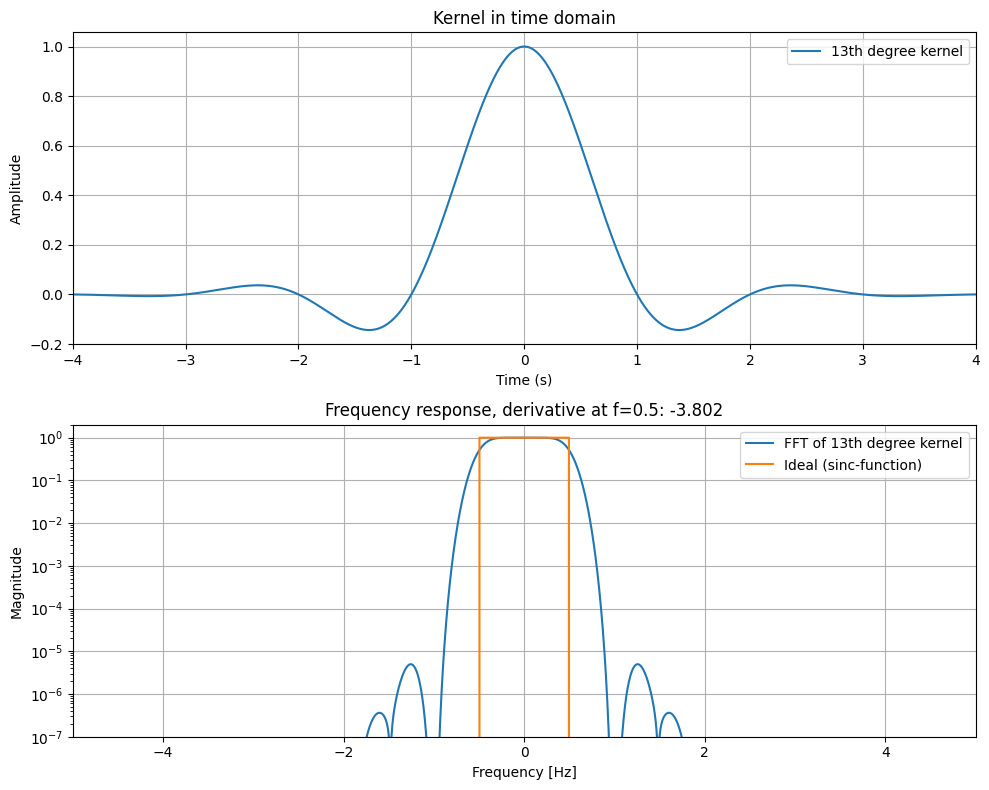
As visible from the plot below, it features a wide range of options in terms of accuracy: Kernels which yield nearest neighbor, linear, cubic, quintic etc. interpolation, all the way up to highly smooth C11 continuous 7th order accurate 13th degree interpolation (I derived these highly accurate kernels myself using SymPy).

Since convolution kernel-based interpolation depend on boundary conditions, I’ve made the package such that it auto-detects the most suitable boundary condition based on the data (linear, quadratic or periodic), but this behaviour can be customized, as explained in the readme.
The boundary handling is the main limitation of this package: When setting up the interpolator, each boundary is extrapolated to create the appropriate boundary condition, which is prohibitive in higher dimensions, due to the many boundary elements. Therefore, there is a trade-off between accuracy and high dimensionality: For high dimensions, using nearest neighbor og linear interpolation requires no boundary condition and should be efficient. As the degree of the polynomial kernel is increased, more boundary condition handling is necessary, increasing the time demand for setting up the interpolator. Also, for high-dimensional data, it is recommended to use the quadratic boundary condition since it is very efficient to evaluate compared to the default auto-detect behaviour.
This package has zero dependencies outside core Julia, so it should be stable over time and require minimal maintenance. I was very inspired by the API design of Interpolations.jl, since my package started out as a PR for that package.
I hope you will check out the package and find it useful. ![]()