This isn’t too practical because each function evaluation requires a numeric integration, but it was a fun way to revisit some math I hadn’t looked at in decades. I smoothed your original function by convolving it with a scaled bump function. This is motivated by 2 facts:
- Convolving a distribution (your function) with a test (bump) function results in an infinitely differentiable function.
- The scaled bump functions approach the delta function in the limit as \epsilon \rightarrow 0 so that you can get an arbitrarily good approximation to your original distribution.
The code and resulting plots for \epsilon = 0.01 are shown below.
using QuadGK: quadgk
using SpecialFunctions: besselk
using Plots
f(x) = max(zero(x), x) # function to be smoothed
half = 0.5 # Can use higher precision type here if desired
const I1 = exp(-half) * (besselk(1, half) - besselk(0, half)) # Integral of unnormalized bump function
bump_unnormalized(x) = abs(x) > 1 ? zero(x) : exp(-1 / (1 - x^2))
bump(x, ϵ=one(x)) = bump_unnormalized(x/ϵ) / (ϵ * I1) # normalized, scaled bump function
# convolve scaled bump function with f
f_smooth(x,ϵ) = quadgk(t -> f(x-t) * bump(t, ϵ), -ϵ, ϵ)[1]
ϵ = 0.01
p = plot(xlabel="x", ylabel="f_smooth(x)", title="ϵ = $ϵ", legend=false, ratio=1)
plot!(p, range(-10ϵ, 10ϵ, 500), x -> f_smooth(x, ϵ), legend=false, ratio=1)
display(p)
p = plot(xlabel="x", ylabel="f_smooth(x)", title="ϵ = $ϵ", legend=false, ratio=1)
plot!(p, range(-ϵ, ϵ, 500), x -> f_smooth(x, ϵ))
display(p)
p = plot(xlabel="x", ylabel="|f(x) - f_smooth(x)|", title="ϵ = $ϵ", legend=false)
plot!(p, range(-10ϵ, 10ϵ, 500), x -> abs(f(x) - f_smooth(x, ϵ)))
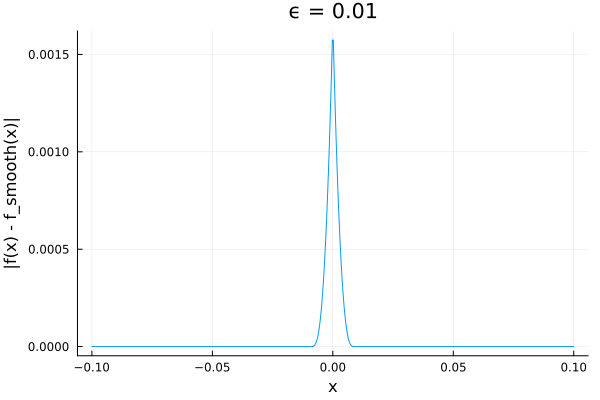
On my machine execution time for invoking f_smooth(x, ϵ) ranges from about 200 nsec for x < ϵ to about 3.5 usec for x > ϵ.
Edit:
Maybe this approach can be cheap enough (on average), since you only need evaluate the smoothed function within the transition region:
f_smoothfaster(x, ϵ) = abs(x) < ϵ ? fsmooth(x, ϵ) : f(x)


