Just want to say how much I appreciate how thoughtful and compassionate you’ve been throughout this thread. You’re setting a high bar for how everyone in OSS could behave.
I want to second that. In particular, @ninjin, I deeply appreciate that you’ve been so careful to take that stance that there is no malicious intent here. On the other hand, there are several other participants here who have implied or even explicitly asserted that I and other core devs of Julia and Pkg have malicious intent or are just greedy, which is both personally hurtful and unwarranted. Ironically, that sort of implication of bad intent actually makes it harder to dispassionately consider whether we should go ahead with the current approach or not. A lot of good technical points have been made here and this issue does deserve more consideration before a final 1.5 release is made.
Yes; there’s a very strong one in my view: the UUID is randomly generated, is unique to Julia, and is not shared with any other service. Your IP address, on the other hand, typically reveals not only your rough geographical location but can also be connected to your activity on every other server on the internet.
I like Julia for many reasons and prefer it over Python ; but Julia isn’t the only choice and Python has already been very widely adopted - so it may be a good idea to compete on other merits e.g. the need for speed, one HPC language etc. and so just follow in their footprints here at least about this:
-
Anaconda Python is opt-in, and has an option to set / unset the flag in the configuration.
-
Specifically re errors posted to core maintainers:
-
In previous versions of conda, unexpected errors resulted in a request for users to consider posting the error as a new issue on conda’s github issue tracker. In conda 4.4, we’ve implemented a system for users to opt-in to sending that same error report via an HTTP POST request directly to the core maintainers.
-
When an unexpected error is encountered, users are prompted with the error report followed by a [y/N] input. Users can elect to send the report, with ‘no’ being the default response. Users can also permanently opt-in or opt-out, thereby skipping the prompt altogether, using the boolean report_errors configuration parameter.
Source: https://readthedocs.com/projects/continuumio-conda/downloads/pdf/latest/
However, as per @johnmyleswhite post here Pkg.jl telemetry should be opt-in - #17 by johnmyleswhite they may, in fact, be covertly tracking more info e.g. server logs that included information like IP addresses than Pkg is proposing to do.
All that being said, I’d guess that the more you have to explain to an IT Security person the more they worry about the software - so it’s probably a good idea to stay on the beaten path here, and compete on other merits e.g. the need for speed, one HPC language etc.
…
Ps> Re: compete on other merits e.g. the need for speed, one HPC language etc.
Consider recent stats on Julia adoption.
-
By January 1, 2019, reports Julialang.org, the total downloads of Julia reached 7.3 million.
-
That number jumped to 12.9 million, a 77 percent increase, by January 1, 2020.
-
The number of published citations for same period rose 66 percent from 1048 to 1680.
-
In his SC19 talk, Edelman noted that as of October 2019 there were 3,119 Julia packages available, up from 1,688 at the year’s start. Those numbers are impressive all around.
It’s not really germane to the rest of the discussion, but automatic collection of crashes, error messages, etc is significantly more sensitive than any of the data being discussed here. For example we now have the new --bug-report option in Julia which is definitely opt in for precisely that reason. I think when comparing these things across ecosystems, it’s important to compare to activity of similar sensitivity and nature. From my best understanding of things what is proposed for Pkg is extremely minimal and entirely standard, it’s just that other people don’t talk about it very much.
I retract that statement: even if using a client uuid implies a potential risk of de-anonymization, that would not mean at all that the data controllers would be able to identify me - or verify my claim of being the user associated to some uuid. In such a situation, a minimal data retention policy like the one presented in the legal notice looks like a reasonable method to ensure the user’s right to data erasure.
With respect to data portability, a local copy of the submitted records might be a solution, as proposed in this issue.
At the risk of derailing:
Assume an organization has set up a private repository with a private package Foo.jl. Would a user within that organization who installs Foo.jl using Pkg be sending telemetry data outside the organization?
I strongly agree with this. For me the UUID is the problem.
They actually are in addition to the UUID, already proposing to use HyperLogLog… (the technical info on what they’re doing is this link that everyone passes around… and discourse then anonymizes) the question is do they need UUIDs at all. And, if they need UUIDs, do they need to be persistent, or could they be rolling… where they remain constant for a while, but after a while, they’re changed. Like an ipv6 privacy address.
No, about 30% of all traffic to google is ipv6. The day you enable an AAAA record on your server you will get a lot of IPv6 traffic. Something like 50% of all people in the US using an internet connection do so via an IPV6 address… something close to 100% of all T-Mobile users have IPv6 ONLY)
This is already the proposal, the UUID is exactly that. So all the objections above to the UUID apply to your proposal. Remember “that cannot id the user or his/her machine” is only true so long as the UUID is a secret. For example in legal proceedings the contents of the computer are discoverable and the UUID then links a person to a potentially decades long history of stuff they did with Julia. If that for example becomes a part of a patent fight, an adversarial divorce proceedings, or a murder investigation (tying say an IP address to a location and time and therefore to opportunity etc) the UUID is potentially very objectionable. IP addresses are much much more deniable.
I too am trying to approach this from a combined technical and social perspective. I don’t believe that Julia has malicious intent, far from it. But I do think that this discussion has brought out all kinds of potentially unintended consequences, from a variety of ways in which this data enables linking of things that were unintended (identity with location or machines and their installed packages / attack vectors). We should remember that no matter how hard Julia tries to keep this private, I’m sure all those companies that lost control of their user databases and credit card data and etc weren’t trying to collect that data so that they could give it to the russian mafia either… this data could become public through malicious action and that’s a scenario in which all the good intentions in the world on the part of Julia can’t reverse the accidental damage that might cause due to the UUID persistently identifying an individual install in a non-plausibly-deniable way.
This is a good point, and it’s the reason that IPv6 privacy addresses exist and are typically randomly regenerated approximately hourly.
the UUID is randomly regenerated approximately NEVER according to current proposals. One specific proposal I’ve made (via issue report) is to use some sort of rolling UUID. I’m now going to go modify that proposal in light of discussions here to something more specific.
I haven’t looked at it that way. (I guess I haven’t looked at it from the viewpoint of a malefactor ;)).
This makes a lot of sense, and I can see why ANY UUID would be a problem.
That’s a good question and is very apropos. This isn’t really classical usage “telemetry” — it’s metadata that gets sent alongside requests you’re already making to a package server. If you’re not getting Foo.jl from a particular package server, then that package server won’t ever know about Foo.jl.
When you instantiate Foo.jl’s project/dependencies, you might hit a public package server, but again, the only information the package server gets is what public packages you’re requesting and their versions… and of course it needs this information in order to actually give those packages back to you.
Further, the package server is user-selectable. If you’re serving private packages within an organization, I highly recommend using a private package server.
Thanks. Just to be clear, then: if an organization uses a private repository to host Foo.jl (and any/all dependencies), no telemetry data will be sent anywhere outside the organization since no requests for code will be made to any repo outside the organization?
(What about adding a package via URL [assume no dependencies]? I would assume that that would also not result in telemetry data being sent.)
That differs from what I know about how IPv6 is used in the wild - namely with the “convenience” of having your network MAC as a part of it, uniquely identifying you even across computer networks. IIRC, this was/is one of the biggest arguments against widespread IPv6 on roaming devices.
As I understand it, if you don’t interact with the public package server and instead host your own, you don’t send telemetry/metadata (IP, timing data, …) to the public instance. This does hinge on your DevOps though and you/your organization is responsible for never connecting to outside ressources.
What @mbauman was saying with “hitting public package server” was when you’re adding dependencies to your private package and source those dependencies from a public package server, of course you’re going to connect to it.
This has been my main goal in participating here, which is to consider the question not of what malicious stuff Julia plans to do with the data, but rather, what malicious stuff could in principle be done if someone else got ahold of the data…
This is the only perspective that matters to a security person and while I’m not primarily a security person, I spend enough time on the OpenWrt forum helping people secure their networks, and reading security bulletins, to know just how much automated and non-automated malfeasance there is on the internet.
I’d also like to have it be very easy to get people like finance industry, banking, utility companies, and etc to adopt Julia in their operations. If I have to explain that there’s an opt out system that otherwise exfiltrates uniquely identifying data but don’t worry … yadda yadda that doesn’t seem conducive to broad adoption in sensitive industries.
There are ipv6 privacy addresses that regenerate on a rolling basis, they’re supported all over the place. There are also so called “persistent privacy addresses” in which the prefix and a secret key are used to generate a persistent address that persists on that prefix but is obviously essentially random across prefixes…
here are some relevant RFCs RFC 4941 - Privacy Extensions for Stateless Address Autoconfiguration in IPv6 and RFC 7217 - A Method for Generating Semantically Opaque Interface Identifiers with IPv6 Stateless Address Autoconfiguration (SLAAC)
All of that has been available and active on most OSes for years.
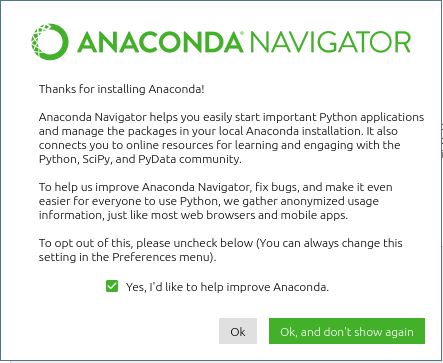
Ok so this is another example where Anaconda Python gives the user an opt-in or opt-out option for what is often being referred to as telemetry in this thread:
When it starts up, you’ll be asked if you want to provide anonymized usage information. If you’re OK with that, click the “OK, and don’t show again” button (otherwise, it asks every time you start it up); if not, uncheck the “Yes, I’d like to help improve Anaconda.” checkbox, then click the “OK, and don’t show again” button.
Is it? Do they have a document anywhere showing excatly what they’re collecting? Genuinely curious. Usage information sounds like exactly the kind of behavioral telemetry that we’re explicitly not collecting.
That was exactly my thought, too. I don’t see anything about this data in the individual EULA, but in the enterprise EULA they note:
- USAGE DATA COLLECTION. Continuum may collect certain non-personal usage data information such as error tracebacks, execution history, and the like, solely for the purpose of bug analysis and feature enhancement. Continuum will make every reasonable attempt to anonymize any Personally Identifiable Information (“PII”) collected in the course of gathering such data.
“non-personal usage data information such as error tracebacks.” Yeah, every file location prefixed by /Users/mbauman/... is totally non-personal. ![]()
The technical aspect is that the telemetry data is sent as extra HTTP headers when Pkg downloads a package from a package server. Thus if a package (and possible dependencies) are added from any other source than a package server, no telemetry is sent at all. If you have configured Julia to talk to a package server within your organization it will send telemetry data but it will stay inside your organization.
Here’s some additional attack vectors I think Julia would agree that they wouldn’t want to inadvertently enable this sort of thing:
Malicious authoritarian government begins crackdown on people enabling secret communications with strong encryption. They arrest dissident and seize his or her computer. They look at the telemetry file and find the UUID. They then exfiltrate the Julia database by some means, remember as a state actor they can do things like threaten providers of TLS certificates and force them to sign whatever certs they want, this offers them all sorts of powers. For example they can potentially remote install their own firmware on the routers of the ISP that Julia uses… Or perhaps the database has already been exfiltrated and put on the darkweb and it’s this that convinces them they can maybe crack down on certain dissidents.
They can now potentially prove that this computer in the possession of this dissident was used to develop Julia based software for encryption and anonymizing free speech, potentially a life-emprisonment or capital offense in said authoritarian country. Julia just accidentally enabled political oppression.
If you think this seems fanciful you are wrong. Consider for example the Fancy Bears or other advanced persistent threats. Consider that some people in the Saudi Government actually had a reporter murdered and dismembered within one of their embassies. Consider that most electronics are manufactured in China, a country with a massive firewall, known to force the sterilization of ethnic minorities etc etc and also known to put backdoors into various routers and cameras and things.
The fact that I’m sure Julia doesn’t want any of these things to happen suggests that keeping track of a UUID which can be direct non-deniable evidence of potentially decades of software activity, some of which might be subject to authoritarian punishment might be more toxic than at first imagined. This is why I have recommended a rolling UUID if an identifier is even needed: https://github.com/JuliaLang/Pkg.jl/issues/1902 and why I modified that suggestion to actually make the history non-reconstructable be regenerating the UUID on a regular basis rather than using my initially proposed mechanism.