Is there an example or a Julia package for piecewise-constant fitting of 1D series?
See a Matlab example of expected results here.
Thanks.
Is there an example or a Julia package for piecewise-constant fitting of 1D series?
See a Matlab example of expected results here.
Thanks.
@stevengj, thanks. Does the fact that it uses the nearest-neighbor imply that it might be a bit off from the expected mean?
What is the “expected mean”?
If you have data from x\in [a,b], and an interpolated function f(x), do you want the continuous mean \frac{1}{b-a} \int_a^b f(x) dx to be something in particular? What? (If you say “I want it to equal the mean of the discrete data points”, stop and think about what this means for the endpoint weighting.) Nearest-neighbor piecewise-constant interpolation corresponds exactly to a trapezoidal rule integration.
Oh, I see — what you want is not piecewise-constant interpolation, but rather piecewise constant least-square fitting. This seems similar to this question, so probably you can use related techniques: Piecewise linear regression with automatic knot selection
Thanks, I have edited the title to not upset the mathematicians ![]()
In any case, I will test the suggested constant interpolation.
If you’re doing least squares why would you want piecewise constant? Why not just use a Chebyshev Polynomials or a Radial Basis Function or similar? Unless you think the underlying function is itself constant and measured with noise I guess.
One application: modelling layered media with layers of constant properties and variable thickness. Where the input data is experimental and continuous, not necessarily noisy. Actually, estimating some optimum K break points is the most important part.
If you’re OK with simple translation from MATLAB, take the code I wrote in matlab - Deconvolution of a 1D Time Domain Wave Signal Convolved with Series of Rect Signals - Signal Processing Stack Exchange. Just use H = I or optimize the code specifically to this case.
This matches the optimization problem in your link.
Yet this is not a Piece Wise Fitting, It is Least Squares with TV regularization which means the prior is a function with sparse derivative. It means it promotes piece wise constant signals.
By the way, for piece wise linear, just adapt the D matrix to calculate the 2nd derivative.
I am copying further below some input data to play with and one example of what might be one piecewise-constant result for K=21 break points:
7.1568
7.1779
7.1707
7.1596
7.1653
7.1862
7.1838
7.1906
7.2034
7.2066
7.2142
7.2077
7.1918
7.1875
7.1846
7.162
7.1749
7.1975
7.2144
7.2129
7.2153
7.2173
7.2085
7.2025
7.1968
7.2113
7.1944
7.2059
7.1945
7.2041
7.2006
7.212
7.2182
7.2208
7.1988
7.2
7.1954
7.2036
7.1996
7.1932
7.1752
7.158
7.1738
7.1557
7.1715
7.1657
7.1661
7.1698
7.1912
7.1963
7.1834
7.1844
7.1723
7.1652
7.1655
7.171
7.1932
7.2004
7.2025
7.2071
7.1973
7.1952
7.1822
7.1818
7.1939
7.2089
7.2245
7.2305
7.2379
7.2357
7.2413
7.2402
7.2466
7.2436
7.2396
7.2429
7.2511
7.2576
7.2497
7.2277
7.2293
7.216
7.213
7.2062
7.2173
7.2192
7.2012
7.192
7.1915
7.187
7.1742
7.1806
7.1703
7.1684
7.1557
7.1716
7.1687
7.1912
7.1935
7.2035
7.1951
7.1881
7.1979
7.2154
7.2178
7.2311
7.2167
7.2066
7.1884
7.1857
7.1937
7.1847
7.2132
7.2082
7.2035
7.2061
7.2091
7.2035
7.1977
7.1838
7.1842
7.197
7.1971
7.1759
7.1782
7.1549
7.1526
7.1572
7.1563
7.1455
7.1567
7.1568
7.1737
7.1712
7.1895
7.1836
7.1975
7.1968
7.1801
7.1589
7.1573
7.1288
7.1342
7.1399
7.162
7.1574
7.1714
7.1652
7.1561
7.1676
7.2022
7.2174
7.2109
7.2062
7.2115
7.2172
7.2227
7.2277
7.2191
7.2251
7.2309
7.2414
7.2402
7.2585
7.2518
7.2619
7.2598
7.2591
7.2475
7.2564
7.256
7.2498
7.2363
7.2426
7.2507
7.2677
7.2608
7.2508
7.247
7.25
7.2563
7.255
7.2465
7.2537
7.2576
7.2591
7.2571
7.2678
7.2697
7.2851
7.2842
7.2846
7.2886
7.2892
7.2925
7.2829
7.2438
7.2457
7.2467
7.2734
7.2845
7.2714
7.267
7.2791
7.2897
7.2829
7.2834
7.2763
7.2733
7.2453
7.2514
7.2471
7.2432
7.2154
7.2403
7.2508
7.2507
7.2619
7.2615
7.2614
7.2736
7.2526
7.2562
7.235
7.237
7.2457
7.2354
7.2358
7.205
7.2095
7.2157
7.2104
7.1955
7.2064
7.2199
7.2293
7.2311
7.2508
7.238
7.212
7.2202
7.2454
7.2407
7.2325
7.2146
7.2386
7.2851
7.2892
7.2839
7.3091
7.3136
7.3313
7.3314
7.329
7.3184
7.3189
7.3051
7.3123
7.3172
7.3097
7.3048
7.3141
7.3241
7.3162
7.3136
7.2911
7.2728
7.2127
7.2453
7.2735
7.2637
7.2686
7.2653
7.2981
7.2869
7.2896
7.281
7.2918
7.2768
7.255
7.251
7.2673
7.2613
7.2529
7.232
7.2498
7.2591
7.2809
7.2903
7.2778
7.2705
7.2492
7.2447
7.2254
7.2435
7.2309
7.2284
7.2601
7.2588
7.2785
7.2979
7.2914
7.2847
7.2939
7.2873
7.2841
7.2766
7.2926
7.2934
7.2989
7.2892
7.3038
7.2971
7.2992
7.2808
7.2734
7.283
7.2797
7.2826
7.2741
7.2825
7.2927
7.2767
7.2839
7.2991
7.2968
7.3004
7.3085
7.3104
7.3199
7.3202
7.309
7.3011
7.3103
7.2999
7.2891
7.2961
7.281
7.2791
7.2583
7.266
7.2711
7.2715
7.2811
7.2882
7.2993
7.3017
7.295
7.2864
7.2943
7.3076
7.3028
7.2997
7.3106
7.3077
7.3129
7.312
7.3172
7.3187
7.3175
7.3226
7.3198
7.3149
7.3249
7.327
7.3179
7.308
7.3149
7.3095
7.306
7.3011
7.3031
7.3004
7.2902
7.2755
7.2861
7.2802
7.2787
7.2784
7.2717
7.2635
7.263
7.285
7.27
7.2698
7.263
7.2684
7.2698
7.2506
7.2457
7.2349
7.2186
7.1928
7.2256
7.2259
7.2078
7.202
7.2362
7.242
7.2412
Isn’t it possible to write the JuMP/Optimization equivalent of the problem from the MATLAB link?
cvx_begin
variable x(n)
minimize( sum_square(y-x) )
subject to
norm(D*x,1) <= K;
cvx_end
from: https://inst.eecs.berkeley.edu/~ee127/sp21/livebook/exa_pw_fitting.html
as noted in OP.
There are a few options with JuMP.
using JuMP, Gurobi, Plots
K = 21
δ = maximum(y) - minimum(y)
model = Model(Gurobi.Optimizer)
set_time_limit_sec(model, 30)
@variables(model, begin
x[1:N]
z[1:N], Bin
end)
@constraints(model, begin
sum(z) <= K - 1
[i=2:N], x[i] - x[i-1] <= z[i] * δ
[i=2:N], x[i] - x[i-1] >= -z[i] * δ
end)
@objective(model, Min, sum((y .- x).^2));
optimize!(model)
plot(y)
plot!(value.(x))
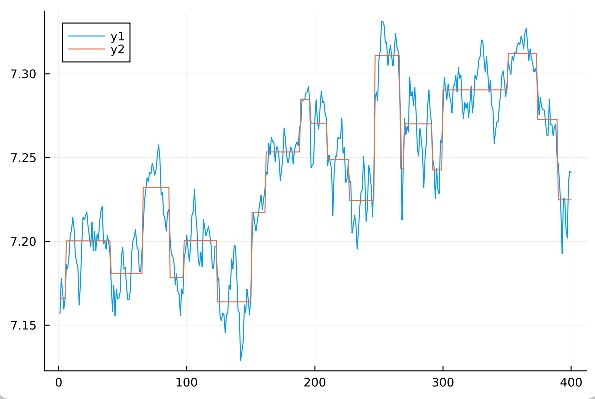
@Dan’s CVX equivalent is:
using JuMP, Gurobi, Plots
N = length(y)
D = zeros(N-1, N);
for i in 1:(N-1)
D[i, i] = -1
D[i, i+1] = 1
end
K = 0.25
model = Model(Gurobi.Optimizer)
@variable(model, x[1:N]);
@objective(model, Min, sum((y .- x).^2));
@constraint(model, [K; D * x] in MOI.NormOneCone(N))
optimize!(model)
plot(y)
plot!(value.(x))
You have to tune K a bit. It doesn’t represent the number of break points.
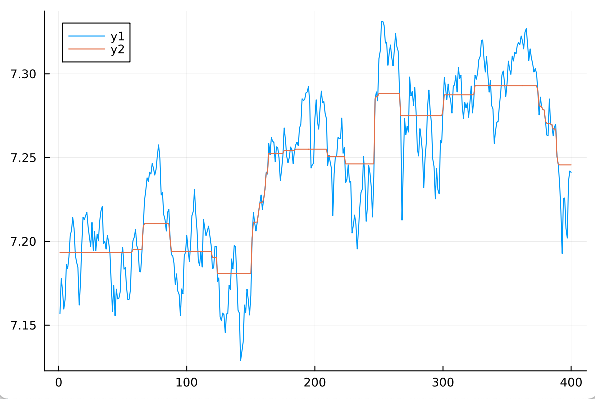
Thanks for the good stuff, the top solution looks brilliant.
Is it possible to constrain it to have a minimum distance between breakpoints, to avoid very short steps? Perhaps as an alternative criteria to fixed K.
Regarding:
This guy needs special installation. Why do we need it? Are there any alternatives?
Is it possible to constrain it to have a minimum distance between breakpoints, to avoid very short steps?
Yes. Constrain z so that it can change value only once in a given window:
window = 10
@constraint(model, [i=window:N], sum(z[i-j+1] for j in 1:window) <= 1)
This guy needs special installation. Why do we need it? Are there any alternatives?
If you’re an academic you can get a free license. We need a mixed-integer quadratic solver. There aren’t many great free alternatives.
If you use the L1 norm for the loss function instead of the L2, then you can use HiGHS:
using JuMP, HiGHS, Plots
K = 21
δ = maximum(y) - minimum(y)
model = Model(HiGHS.Optimizer)
set_time_limit_sec(model, 30)
@variables(model, begin
x[1:N]
z[1:N], Bin
t
end)
window = 10
@constraints(model, begin
sum(z) <= K - 1
[i=window:N], sum(z[i-j+1] for j in 1:window) <= 1
[i=2:N], x[i] - x[i-1] <= z[i] * δ
[i=2:N], x[i] - x[i-1] >= -z[i] * δ
[t; y .- x] in MOI.NormOneCone(1 + N)
end)
@objective(model, Min, t);
optimize!(model)
plot(y)
plot!(value.(x))
Thank you, this is brilliant.
I like the L1 norm results too.
You could do a nice Bayesian model in Turing. A prior on the distance between nodes, a Normally distributed error, and a prior on the jump sizes, then cumsum the x values and the Y values… You’d get a comprehensive sample of plausible fits.
I know you have a solution already, but I wanted to see if I could work this problem without using sophisticated optimizers. Here is my effort:
using Statistics
struct Segment{T}
x1::T
x2::T
y::T
end
function piecewiseconst(x::AbstractVector, y::AbstractVector, maxerr::Real, minwindow::Int=10)
length(x) == length(y) || error("x and y have unequal lengths")
ymid, ymax = quantile(y, (0.5, 0.8))
value = ymid
err = ymax - ymid
segment = Segment(x[begin], x[end], value)
if err ≤ maxerr || length(x) < max(minwindow, 3)
return [segment]
else
bind = firstindex(x)
eind = lastindex(x)
mind = (bind + eind) ÷ 2
l = piecewiseconst(view(x, bind:mind), view(y, bind:mind), maxerr, minwindow)
r = piecewiseconst(view(x, mind:eind), view(y, mind:eind), maxerr, minwindow)
return vcat(l, r)
end
end
The function returns a Vector{Segment} comprising the piecewise constant approximation to the input data. Here is how to apply it to your data and plot the result:
using Plots, DelimitedFiles
ypts = readdlm("sampledat.txt")[:]
xpts = [float(i) for i in 1:length(ypts)]
function plotit()
p = plot(xpts, ypts, color=:blue, legend=:none)
yold = ypts[begin]
for (i, s) in enumerate(segs)
x1, x2, value = s.x1, s.x2, s.y
if i == 1
x = [x1, x2]
y = [value, value]
else
x = [x1, x1, x2]
y = [yold, value, value]
end
plot!(x, y, color=:red, lw=2)
yold = value
end
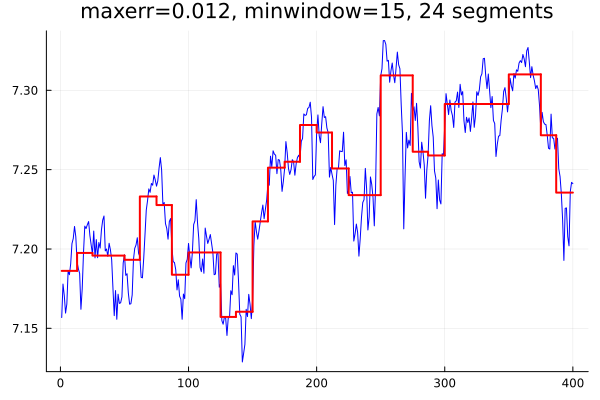
plot!(p, title = "maxerr=$maxerr, minwindow=$minwindow, $(length(segs)) segments")
display(p)
end
maxerr = 0.012
minwindow = 15
segs = piecewiseconst(xpts, ypts, maxerr, minwindow)
plotit()
The resulting plot looks like this:
For interest (I like the elegance of the integer optimisation approach) your method reminded me of a principle put forward by de Boor that:
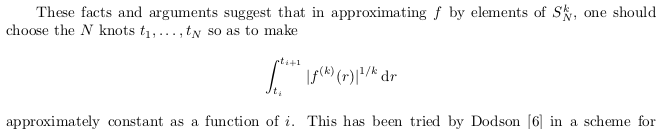
The below implements this idea fairly simply (for k = 1 in the equation above):
using DelimitedFiles, Statistics
# Set number of segments
K = 21
# Get data:
y_data = readdlm("sampledat.txt")[:]
N = length(y_data)
x_data = 1:N
# Define breakpoints / knots (include the endpoints)
t = zeros(Int,K+2) # To be determined
t[begin] = 1
t[end] = N
# Define function values over segments
f = zeros(K+2) ## To be calculated
f[begin] = y_data[begin]
f[end] = y_data[end]
y_diff = [abs(y_data[n+1] - y_data[n-1]) for n in 2:(N-1)]
# Sum of absolute values of data:
S = sum(y_diff)
# Constant contribution on each segment:
T = S/(K+1)
C = cumsum(y_diff)
t[(begin+1):(end-1)] = [Int(argmin(abs.(C .- k*T))) for k in 1:K]
# The best fit value over a single segment is the mean:
for i in 1:K+1
f[i] = mean(y_data[t[i]:t[i+1]])
end
using Plots
function plot_pwc_data(indices,values)
x = [indices[begin]]
y = [values[begin], values[begin]]
for i in 2:(length(indices)-1)
push!(x, indices[i], indices[i])
v = values[i]
push!(y, v, v)
end
push!(x, indices[end])
return x, y
end
p = plot(x_data, y_data, color=:blue, legend=:none)
plot(p)
tt, ff = plot_pwc_data(t,f)
plot!(tt, ff, color=:red, lw=2)
@PeterSimon & @jd-foster, thanks for the nice out-of-the box ideas, which provide food for thought.
@jd-foster, btw, plot_pwc_data() could be conveniently replaced by:
plot!(t, f, lt=:step, c=:red, lw=2)
What about the Pelt algorithm for id’ing change points? “Optimal detection of changepoints with a linear computational cost.”


