Hello,
I’m measuring the latency of mul!(C, A, B), where C and B are dense and A is sparse, and I’m seeing something surprising: the latency isn’t linear in the number of operations required. Does anyone know why this is?
The number of columns of A is m=1000, the number of columns of B is k=3, and I’m varying the number of rows of A, denoted by n. I’m on an Intel system and I’m including MKLSparse (but I see the same behaviour regardless of if I use MKLSparse).
My experiment looks like the following code, except that it’s in a function, I’m running it many times, and I discard the first sample (since it includes compilation time)
A = sprand(n, m, 0.05)
B = randn(m, k)
C = zeros(n, k)
latency_mul = @elapsed mul!(C, A, B)
latency_mymul! = @elapsed mymul!(C, A, B) # mymul! defined below
Here’s the definition of mymul!:
function mymul!(C::Matrix, A::SparseMatrixCSC, B::Matrix)
@boundscheck size(C, 1) == size(A, 1) || throw(DimensionMismatch("C has dimensions $(size(C)), but A has dimensions $(size(A))"))
@boundscheck size(C, 2) == size(B, 2) || throw(DimensionMismatch("C has dimensions $(size(C)), but B has dimensions $(size(B))"))
@boundscheck size(A, 2) == size(B, 1) || throw(DimensionMismatch("A has dimensions $(size(A)), but B has dimensions $(size(B))"))
m, n = size(A)
k = size(B, 2)
rows = rowvals(A)
vals = nonzeros(A)
C .= 0
for col = 1:n # column of A
for i in nzrange(A, col)
@inbounds row = rows[i] # row of A
@inbounds val = vals[i] # A[row, col]
@simd for j = 1:k # columns indices of B
@inbounds C[row, j] += val * B[col, j]
end
end
end
C
end
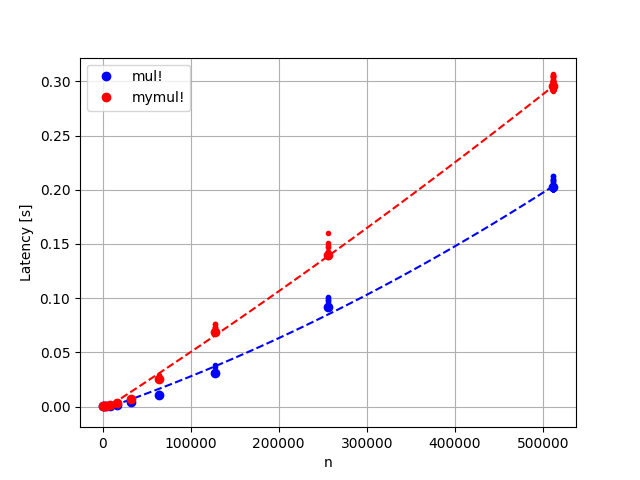
This is the latency I’m seeing. I’d have expected that latency would increase linearly with the number of rows, which is what I’m seeing for mymul! (ish, for large enough matrices). However, for mul! I see something else. The dashed lines are quadratic functions fit to the data. The latency looks linear in the number of rows when running the same experiment for dense matrices so it’s got something to do with the sparse matrix multiplication.