Quick question: suppose I have a DataFrame of the form
df = DataFrame(grouping1 = [1, 1, 2, 2], grouping2 = [true, true, true, false])

Even though, for the grouping1 category: 1, there are no observations with grouping2 value: false, I would like to then count observations forcing a homogenous nesting across grouping1 values so that when I do something along the lines of:
df = combine(DataFrames.groupby(df, [:grouping1, :grouping2]), nrow)
Instead of getting this:
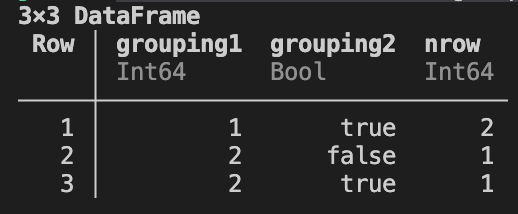
I get what I refer to a balanced df where fro grouping1 value 1, grouping2 has two values too and false would apear to have 0 counts.
This seems like useful when structuring data into nests and I thought there would be some function/option already available but I cant seem to find one.

julia> gdf = groupby(df, :grouping1);
julia> combine(
gdf,
:grouping2 => count => :trues,
:grouping2 => (count ∘ .!) => :falses,
)
2×3 DataFrame
Row │ grouping1 trues falses
│ Int64 Int64 Int64
─────┼──────────────────────────
1 │ 1 2 0
2 │ 2 1 1
I would just create a new data frame that has all the combinations present. You can use the function allcombinations for this
julia> df = DataFrame(grouping1 = [1, 1, 2, 2], grouping2 = [true, true, true, false])
4×2 DataFrame
Row │ grouping1 grouping2
│ Int64 Bool
─────┼──────────────────────
1 │ 1 true
2 │ 1 true
3 │ 2 true
4 │ 2 false
julia> df_complete = allcombinations(DataFrame, grouping1 = [1, 2], grouping2 = [true, false])
4×2 DataFrame
Row │ grouping1 grouping2
│ Int64 Bool
─────┼──────────────────────
1 │ 1 true
2 │ 2 true
3 │ 1 false
4 │ 2 false
julia> df_collapsed = @chain df begin
groupby([:grouping1, :grouping2])
combine(nrow)
leftjoin(df_complete, _, on = [:grouping1, :grouping2])
@transform :nrow = replace(:nrow, missing => 0)
end
4×3 DataFrame
Row │ grouping1 grouping2 nrow
│ Int64 Bool Int64
─────┼─────────────────────────────
1 │ 1 true 2
2 │ 2 true 1
3 │ 2 false 1
4 │ 1 false 0
If you are willing to live with missing instead of zero counts you can achieve this with
julia> unstack(
combine(
groupby(
df,
[:grouping1, :grouping2],
),
nrow => :n,
),
:grouping2,
:n,
)
2×3 DataFrame
Row │ grouping1 true false
│ Int64 Int64? Int64?
─────┼────────────────────────────
1 │ 1 2 missing
2 │ 2 1 1
I guess to get the result the OP wants you would need to stack after unstacking.
It’s a bit more compact to use column numbers instead of names in this case.
julia> stack(unstack(combine(groupby(df, 1:2), nrow => :n), 2, :n), 2:3)
4×3 DataFrame
Row │ grouping1 variable value
│ Int64 String Int64?
─────┼──────────────────────────────
1 │ 1 true 2
2 │ 2 true 1
3 │ 1 false missing
4 │ 2 false 1
Another option, which might be simpler for non-experts of the DataFrames’ mini-language:
df_all = allcombinations(DataFrame, grouping1=[1, 2], grouping2=[true, false])
df_all.count = [count(values(c)==values(r) for r in eachrow(df)) for c in eachrow(df_all)]
df_all