The whole parallelization, it would be nice to have hybrid-parallelization with threading and MPI style area decomposition such a way that InfiniBand is also supported. Same very user-friendly way as the normal julia experience at the moment.
Some new benchmark data with @kristoffer.carlsson’s fixes for int parsing and printing ( #28661, #28670)
| 0.6.4 | 1.0.0 | 1.0.0-DEV | |
|---|---|---|---|
| iteration_pi_sum | 27.37 | 27.66 | 27.68 |
| matrix_multiply | 70.24 | 70.32 | 70.33 |
| matrix_statistics | 8.513 | 7.323 | 7.30 |
| parse_integers | 0.132 | 0.218 | 0.163 |
| print_to_file | 6.860 | 10.870 | 6.50 |
| recursion_fibonacci | 0.0406 | 0.0302 | 0.0302 |
| recursion_quicksort | 0.248 | 0.259 | 0.261 |
| userfunc_mandelbrot | 0.0565 | 0.0527 | 0.0527 |
| relative to C | 1.097 | 1.168 | 1.057 |
The relative-to-C numbers are geometric means relative to C compiled with gcc-7.3.1, computed this week. In previously published benchmarks julia-0.6.2 was at 1.05 relative to C with gcc-4.8.3, so I think gcc must have improved between these versions.
At the risk of attaching too much meaning to it, I’m pleased to report that julia-1.0.0-DEV is now the fastest non-C language on the microbenchmark suite.
| language | geomean |
|---|---|
| C | 1.0 |
| Julia | 1.057 |
| LuaJIT | 1.091 |
| Rust | 1.099 |
| Go | 1.48 |
| Fortran | 1.67 |
| Java | 3.46 |
| JavaScript | 4.79 |
| Matlab | 9.56 |
| Mathematica | 14.62 |
| Python | 16.91 |
| R | 48.5 |
| Octave | 338.3 |

It seems to include both startup and compilation time.
Which is insignificant since the benchmark takes ~10s.
At this point I think I get more satisfaction out of Mathematica beating Python than Julia beating everything ![]() .
.
NOTE: The GNU implementation is using a
constexprwhich optimizes the recursive call to a constant. It breaks the benchmark since it doesn’t perform the same tasks as the other languages. It demonstrates that all benchmarks will have some caviat. Without theconstexpr, GNU C++ is on par with the clang version at 6.159s.
Running with julia -O3 gets it down to around 9 secs on my machine, which would put it in the top 10. PR? EDIT: Julia 1.0
It would be interesting to also include the MKL version of Julia, at least two benchmarks will be improved, matrix_multiply and matrix_statistics. This is fair since Luajit and MATLAB use MKL, I’m not sure about the others.
Matrix multiply won’t change much. It’s things like some factorizations (QR, SVD) where MKL makes a difference.
I think, and numbers show, differently (The benchmark will be updated once JuliaPro 1.x.xxx MKL + JuliaPro 1.x.xxx OpenBLAS will be released, Currently I think it is Julia 0.5 vs. MATLAB R2016b):
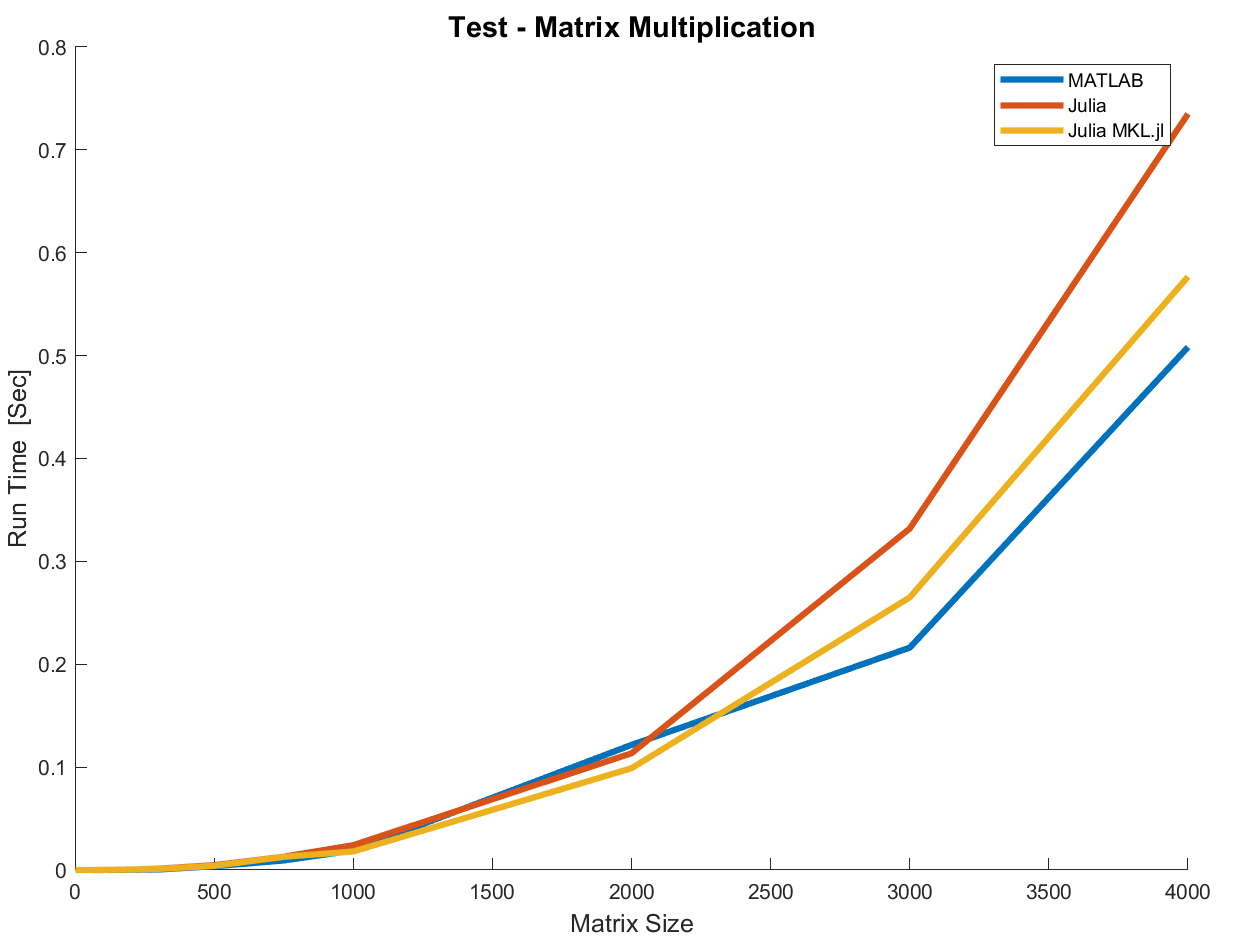
If you use MKL Direct Call things will get even better fro small matrices.
Let’s not go through all that again but OpenBLAS is still not up there with MKL in most performance metrics.
@Seif_Shebl, Why do you think LuaJit uses MKL?
You didn’t show any numbers, just Julia vs MATLAB. In actual benchmarks that actually test Julia OpenBLAS vs Julia MKL, they do not show a meaningful difference in matrix multiplication.
If MATLAB is doing well there then it’s doing something more. And it’s not small matrices since even your benchmark shows Julia is doing fine on small matrices.
No, let’s be specific about where the differences are. You show a difference between MATLAB and Julia. But benchmarks of Julia MKL vs Julia OpenBLAS do not show such differences. This is interesting and you shouldn’t just throw it off as “but MATLAB uses MKL, let’s go get MKL” because that is inconsistent with the benchmark results, unless there is something unexplained! IMO that is definitely something that needs to be pointed out and addressed.
It might have to do with build settings. Maybe @barche can chime in.
Driven by the advances in deep learning and computer vision, Intel has lately worked on optimizing small matrix-matrix multiplication functions. These functions rely on true SIMD matrix computations, and provide significant performance benefits compared to traditional techniques that exploit multithreading but rely on standard data formats. So, I think if we build Julia against the latest MKL versions, we can achieve significant gains over OpenBLAS even with tiny matrices.
Here is also this presentation on how to Speed Up Small-Matrix Multiplication using New Intel® Math Kernel Library Capabilities.
Yes I agree but that still doesn’t account for the performance difference with larger matrices.
I am curious, do you know of similar opportunities to improve the speed of factorizations (LU, QE; SVD) of small matrices?
@ChrisRackauckas,
Do you believe the difference between Julia + OpenBLAS to MATLAB + OpenBLAS is due to overhead?
Because I believe both just do a regular BLAS call with minimal overhead.
MATLAB doesn’t have special API to extract better performance from MKL.
Anyhow, Once version 1.x.xxx of JuliaPro will be available we’ll be able to check those numbers again.
I still think Julia should use the Direct Call API of MKL.
It seems it will have great effect on small matrices to a point it will (Maybe) be faster the StaticArrays.
@Seif_Shebl, Could you tell why do you think LuaJit was using Intel MKL in the tests above?
No. For large matrices the cost of the multiply is so much larger than the overhead that it wouldn’t even register there. And you both show that there’s no difference for small matrices which is where overhead would be seen. There is something deeper going on.
As I said, I would check to see if it’s due to how it’s built. Instead of using JuliaPro MKL, build Julia with MKL yourself and see if that makes a difference. Then play with build flags.
If I understand it correctly, the test comparing Matlab with Julia for matrix multiplication shown by @RoyiAvital is a bit dated. Wouldn’t it be wise to get current numbers before jumping to conclusions?
I rather not build stuff my self unless it is a code I created (I’m not very good at this unfortunately).
Searching for other comparisons of MKL vs. OpenBLAS on R and Numpy they all show (Though most of them are ~2 years old, yet the numbers you brought are 2 yeas old as well) MKL is faster.
Few more weeks and we’ll have a clearer picture (JuliaPro MKL vs. JuliaPro OpenBLAS vs. MATLAB R2018a / R2018b).
If we’ll see Julia with MKL on pure BLAS calls is much slower than MATLAB it means something isn’t right.
From the link above:
The latest version of Intel MKL adds six compact functions:
- General matrix-matrix multiply
- Triangular matrix equation solve
- LU factorization (without pivoting)
- Inverse calculation (from LU without pivoting)
- Cholesky factorization
- QR factorization