I like that idea. Do you know how much resources not loading LinearAlgebra would save? I’m always on the lookout for statistics about Julia’s memory usage but it’s rare to see concrete numbers.
Also all these settings could be handled by juliaup default settings. It could even recommend not loading it by default for heavy linear algebra users.
I just built two versions of julia:
- A regular
git cloneof therelease-1.11branch - The
release-1.11branch, but with Line 84 ofbase/sysimage.jlcommented out so that the sysimage does not include linear algebra. (If there’s something else I need to do here that I’m missing, someone please let me know!)
I find that without LinearAlgebra, opening a REPL and no packages has an idle memory usage of 205.0 MiB on my machine, whereas the one with LinearAlgebra uses 218.0 MiB. (so 13 MiB saved, I suspect this is not counting OpenBLAS?)
For startup times, I find
Without LinearAlgebra:
❯ hyperfine './julia --startup=no -e "1 + 1"'
Benchmark 1: ./julia --startup=no -e "1 + 1"
Time (mean ± σ): 90.3 ms ± 2.1 ms [User: 43.5 ms, System: 50.0 ms]
Range (min … max): 87.1 ms … 94.7 ms 31 runs
With LinearAlgebra:
❯ hyperfine './julia --startup=no -e "1 + 1"'
Benchmark 1: ./julia --startup=no -e "1 + 1"
Time (mean ± σ): 101.4 ms ± 2.3 ms [User: 52.6 ms, System: 55.4 ms]
Range (min … max): 96.2 ms … 105.4 ms 28 runs
So a measurable improvement in load times and memory consumption, though I’d say hardly an improvement worth breaking people’s code over.
I am not an expert in these things, but I recently saw a discourse discussion on a package and startup file that would load a package as soon as it was needed. Perhaps making something like this built into Julia might resolve some of the issues discussed here?
I personally would accept
julia> randn(3,3) * randn(3,3)
ERROR: MethodError: no method matching *(::Matrix{Float64}, ::Matrix{Float64})
To enable linear algebra operations, add `import LinearAlgebra` to your
module, script, or REPL.
An error hint precisely defines the trivial fix. But this would still be the breaking-est change since v1.0, so I don’t think it really has a future.
But I don’t think a half-way solution that enables * but not every other function (exp, acosh, etc.) is really doing a great job of solving the problem. Even if we get past *, sooner or later we’ll have this same error (or a more esoteric one that complains about gebal! or something).
Old scripts that used to run fine but now are 10x slower with naive matmul will still “need to” (okay fine, “definitely should”) be modified to regain their old performance. The penalty is so high that I think I’d rather throw an error and force the user to fix it (which is a fix applied globally from virtually anywhere – thanks, piracy!) than limp along with a mediocre fallback.
That could be given a clean error too.
It’s not 10x, and actually the fallbacks are faster than OpenBLAS in many scenarios on many chips. The performance difference is really not uniform and OpenBLAS has a bad enough threading cost model that we have measured many scenarios where it’s not a clear win.
Most of the motivations here, though, are around juliac/PackageCompiler.jl-ish workflows, no? The former is new and experimental and could reasonably require explicit inclusion of stdlibs in the environment (especially in conjunction with --trim), and the latter similarly allows that, albeit not as the default.
Surely this is low on the list of what you’d want to optimize in an interactive/non-compiled context. There are much bigger fish to fry there. Or am I missing another motivating usecase?
There are multiple intersecting problems pointing in this direction. You identified just one. Here’s the list:
- OpenBLAS is generally not the right solution or BLAS for a given problem or system. Talking about the 10x, many people can 10x by switching to MKL or AppleAccelerate. Our tests across SciML users has shown that like 80% of users seem are about an order of magnitude slower than they should be (because OpenBLAS is particularly bad at LU), and yet many people (even in this thread) don’t even know to switch from OpenBLAS because it’s so baked in.
- OpenBLAS being baked in leads to latency and startup issues. Not all interactive contexts need to pay this price, but everyone does. This is compounded by folks who should be using a different BLAS (which again, at least from our LU tests, that is basically everyone not using an AMD EPYC chip, so even Ryzen) is paying this price. And of course, workflows not using BLAS are paying this price.
- It leads to extra issues when trying to build binaries. Yes there are some solutions with trimming, but they aren’t great. In particular, we don’t have a solution for small control systems, where you want to do things for 20x20 matvecs, where the simple loop matvec is about as fast as OpenBLAS but then we still hit that code path. Being able to set “please no BLAS, but don’t just fail just do the easy thing it’s good enough for this chip” would be the right solution
- Alternative compilations are becoming more common. For example, compilation to WASM, standard DiffEq has issues because many codes assume you will hit BLAS. It can be difficult to effectively turn this behavior off because it’s baked in. In this case the “just work” behavior is likely what you want, not “let’s wait until BLAS compiles to WASM”.
- Julia’s norms are generally to opt into performance, not opt out. This is against the trend.
With all of these factors coming together, that’s where I start to ask if the cost of baking in OpenBLAS is no longer worth the benefit. It makes it harder to point to the right BLAS (so it limits people from actually hitting the best performance), while not necessarily being simpler in lots of use cases. Is a set of simple implementations plus a warning (that can be turned off) that much harder to use?
Honestly I see this often where we start baking in latency in order to force people to get the fastest thing by default so it’s not possible to benchmark us poorly. I’ve recently been pulling back on this. With LinearSolve.jl, we know that most people should use RecursiveFactorization.jl, but we have removed it by default for lower latency. We now require the user using it, and if they do, it puts itself back into the recommendation algorithm.
What I really am wishing for is a separate logging system for performance warnings. Something where you can give information about what you probably should do differently for those who care. BLAS warnings go there. Adding accelerator packages like LoopVectorization go there. We are depending on everything because we don’t have the right escape outlet to talk to users about this stuff, we have silence or defaults, but I think we really want a third triggerable option.
Right, you’re not really talking about excising LinearAlgebra from the standard sysimage anymore, but rather wholesale replacing and re-implementing OpenBLAS in Julia. And that could surely bring many other advantages (thanks in part to its imaginariness), I get that.
But then doesn’t this hypothetical JuliaBLAS just become your new baked-in-enemy-that-people-don’t-know-to-replace, just with a different set of tradeoffs? I see how the warning system might “solve” that, but that’s yet another very different can of worms.
With warnings, there’s always a chance that the user doesn’t see them. E.g. in the HPC setting, if the user’s running a batch job, they might not look at the batch log if the job succeeds. But an HPC setting might be one where performance actually is really important to the user.
Make BLAS backend a ScopedValue ![]()
I haven’t done detailed benchmarks myself, but from everything I’m reading, this seems exaggerated lacks important nuance. Here’s a big Accelerate performance discussion with lots of benchmarks: BLAS support for M1 ARM64 via Apple's Accelerate · Issue #869 · JuliaLang/LinearAlgebra.jl · GitHub. Some takeaways:
- Accelerate mainly shines for matmuls, less so for factorizations and solves. This makes sense because the AMX coprocessor architecture is more reminiscent of GPUs. For
eigen, you’re almost always better off using OpenBLAS.luis more of a wash since that factorization fits this kind of architecture better. - Accelerate mainly shines for smaller problems, while OpenBLAS scales better with size. Which matmul is faster at larger sizes (
N > 1000or so) depends on the exact chip. This is likely related to the apple chips having 2-3 AMX coprocessors but a lot more regular performance cores, so OpenBLAS can parallelize more. - Accelerate can be quite slow for complex numbers. This may also be chip-/version-dependent, but in some benchmarks, OpenBLAS wins already at
N ~ 100.
Caveat that some of the benchmarks supporting these takeaways may be somewhat outdated. Accelerate is tied to the macOS version and has improved over time. For one, they fixed a bug in the pivoted cholesky implementation that was discovered by the julia test suite: Add support for ILP64 Accelerate by staticfloat · Pull Request #113 · JuliaLinearAlgebra/libblastrampoline · GitHub
Finally, starting with Apple M4 chip, the AMX instruction set is open-source and OpenBLAS is working on implementing matmul kernels for it (see Support for SGEMM_DIRECT Kernel based on SME1 by vaiskv · Pull Request #5084 · OpenMathLib/OpenBLAS · GitHub and [WIP] Arm®v9-A architecture SME2 SGEMM kernels by AymenQ · Pull Request #5011 · OpenMathLib/OpenBLAS · GitHub). So expect Accelerate’s advantage to shrink over time (though, sadly, these improvements won’t apply to M1-M3 chips).
All that to say, I don’t think OpenBLAS is a particularly bad default on apple silicon, even though Accelerate is clearly preferable for workloads mainly consisting of small to medium-size real matmuls. FWIW, I’m deliberately using OpenBLAS instead of Accelerate in my current project because it’s marginally faster for this particular workload on my M4, and it also seems to incur slightly less numerical error.
That’s a strawman. I just want a simple but stable implementation, none of the extra cache aware implementation stuff. Just a reference BLAS shipped by default. It’s not imaginary since there are already reference BLASes we can choose from. Here is one: GitHub - Reference-LAPACK/lapack: LAPACK development repository . A mix of reference BLAS and simple Julia fallbacks (which mostly already exist in things like GenericLinearAlgebra.jl and within LinearAlgebra.jl) would be the foundation.
I did oversimplify because I was doing it from my phone. Let’s share the real information then. LU Factorization Benchmarks · The SciML Benchmarks On tuned systems, Blue = OpenBLAS. GFLOPS => higher is better. Simplest data I can share right now while traveling:
julia> versioninfo()
Julia Version 1.9.1
Commit 147bdf428c (2023-06-07 08:27 UTC)
Platform Info:
OS: Windows (x86_64-w64-mingw32)
CPU: 32 × AMD Ryzen 9 5950X 16-Core Processor
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-14.0.6 (ORCJIT, znver3)
Threads: 32 on 32 virtual cores
Environment:
JULIA_IMAGE_THREADS = 1
JULIA_EDITOR = code
JULIA_NUM_THREADS = 32

julia> versioninfo()
Julia Version 1.10.0-beta1
Commit 6616549950e (2023-07-25 17:43 UTC)
Platform Info:
OS: macOS (arm64-apple-darwin22.4.0)
CPU: 8 × Apple M2
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-15.0.7 (ORCJIT, apple-m1)
Threads: 1 on 4 virtual cores
Environment:
JULIA_NUM_PRECOMPILE_TASKS = 8
JULIA_DEPOT_PATH = /Users/vp/.julia
JULIA_PKG_DEVDIR = /Users/vp/.julia/dev

Julia Version 1.11.0-DEV.235
Commit 9f9e989f24 (2023-08-06 04:35 UTC)
Platform Info:
OS: Linux (x86_64-linux-gnu)
CPU: 8 × 11th Gen Intel(R) Core(TM) i7-1185G7 @ 3.00GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-15.0.7 (ORCJIT, tigerlake)
Threads: 6 on 8 virtual cores
Environment:
JULIA_NUM_THREADS = 4,1

julia> versioninfo()
Julia Version 1.9.1
Commit 147bdf428c (2023-06-07 08:27 UTC)
Platform Info:
OS: Windows (x86_64-w64-mingw32)
CPU: 8 × 11th Gen Intel(R) Core(TM) i7-1165G7 @ 2.80GHz
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-14.0.6 (ORCJIT, tigerlake)
Threads: 1 on 8 virtual cores
Environment:
JULIA_IMAGE_THREADS = 1

julia> versioninfo()
Julia Version 1.9.3
Commit bed2cd540a (2023-08-24 14:43 UTC)
Build Info:
Official https://julialang.org/ release
Platform Info:
OS: Windows (x86_64-w64-mingw32)
CPU: 32 × AMD Ryzen 9 3950X 16-Core Processor
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-14.0.6 (ORCJIT, znver2)
Threads: 16 on 32 virtual cores
Environment:
JULIA_NUM_THREADS = 16
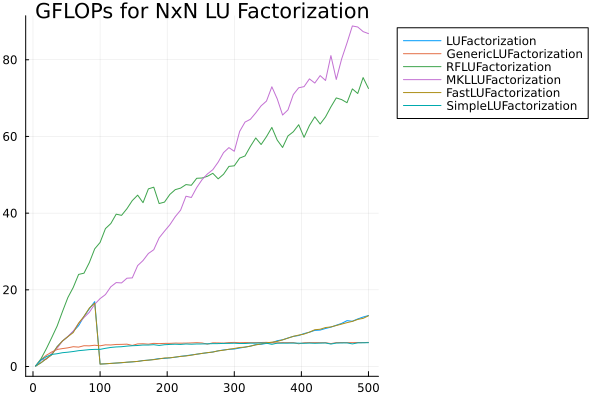
And then the outlier is of course AMD EPYC (notice that before, where OpenBLAS is really bad is AMD Ryzen, so the chip matters)
Julia Version 1.10.4
Commit 48d4fd48430 (2024-06-04 10:41 UTC)
Build Info:
Official https://julialang.org/ release
Platform Info:
OS: Linux (x86_64-linux-gnu)
CPU: 128 × AMD EPYC 7502 32-Core Processor
WORD_SIZE: 64
LIBM: libopenlibm
LLVM: libLLVM-15.0.7 (ORCJIT, znver2)
Threads: 1 default, 0 interactive, 1 GC (on 128 virtual cores)
Environment:
JULIA_CPU_THREADS = 128
JULIA_DEPOT_PATH = /cache/julia-buildkite-plugin/depots/5b300254-1738-4989-ae0a-f4d2d937f953

Notice that here, OpenBLAS isn’t good just MKL is really bad. Hmm Intel… what happened to the performance of MKL on the AMD server chips… interesting coincidence.
My conclusion is, why are we choosing OpenBLAS for everyone?
Thanks for sharing! I concede that, for LU of these sizes, vendor-provided BLAS/LAPACK reliably outperforms OpenBLAS by about 2x on both Intel and Apple. MKL is also surprisingly good on AMD. (There’s a wrinkle worth being aware of for Apple: AppleAccelerate.jl doesn’t respect BLAS.set_num_threads, so you should really use the environment variable VECLIB_MAXIMUM_THREADS to ensure fair comparisons. (Something to consider for SciMLBenchmarks?) However, I just checked on my M4: LU factorization of a 500x500 matrix isn’t sensitive to this variable, and I can reproduce the 2x advantage over OpenBLAS with VECLIB_MAXIMUM_THREADS=1, so this benchmark came out fair anyway.)
That said, the benchmarks in the issue I linked earlier show that the picture can look quite different for different operations, so it might be premature to conclude about the best/worst default based only on LU benchmarks.
In any case, the main story I see in these plots is the absolutely atrocious OpenBLAS performance on AMD Ryzen chips. What on earth is going on there? Those benchmarks were all run on Julia 1.9; does anyone know if this is improved in the newer OpenBLAS versions shipped with newer Julia versions?
Ryzen, yes. EPYC no. It’s a very funny distinction that the server chips just happen to be that bad. Interesting, completely random I assume.
Yeah there’s still nasty side issues here and there. I think that’s because using an alternative BLAS is still considered so non-standard that it’s not a well-trodden path. It’s okay for those paths to be less tested and covered because everyone uses OpenBLAS.
OpenBLAS doesn’t really get that much maintenance these days. It can take awhile to update to new architectures. In particular, it can be really bad at threading models on new chips.
The SciMLBenchmarks updates this often LU Factorization Benchmarks · The SciML Benchmarks and I haven’t seen it budge lately. But it only runs on EPYC so it’s not a complete picture. I want to setup a script that I can give to people that will run on their computer and automatically uploads the data to an issue/repo for analysis.
Mind you, one of the things missing here is that AMD has their own BLAS https://www.amd.com/en/developer/aocl/dense.html that we just don’t have accessible from Julia yet. I’m hoping to get binaries there to test how that goes as well, but it’s based on BLIS and I would assume from other external benchmarks that it should similarly outperform OpenBLAS like how MKL does on Intel.
Maybe it was the case in the past, but I don’t think that’s accurate nowadays. A couple of years ago they got a Sovereign Tech Fund grant (Julia was also explicitly mentioned in the description of the project), with which they improved a lot CI machines. And in general in my experience when we had problems with OpenBLAS in Julia they were always dealt with reasonably quickly (in the matter of days if not hours), for what’s mainly a one-man project, recent cases: 1, 2, 3, 4, 5.
I haven’t done much matrix arithmetic in Julia, but I’ve written some C++ programs that do matrix arithmetic, and I wrote the matrix module with pairwise addition.
I think it would be a good idea.